...
| Info |
|---|
Пример URL для файла: http://example.com/file |
...
Результатом работы потока будет таблица в BQ с полями, указанными в наборе данных:
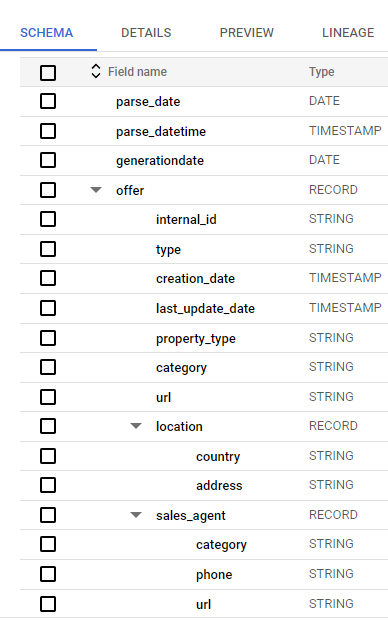
Дальнейшая работа с данными
После того, как мы распарсили наш фид к этим данным можно обращаться при помощи SQL запросов, а это означает, что можно сделать YRL на основе выбранных данных.
...
| Expand | ||
|---|---|---|
| ||
Авторизовавшись в системе Garpun переходим в раздел "Подключения"(ссылка), Выбираем Google BigQuery, нажимаем "+подключение".
|
Anchor feed-start feed-start Источник данных > Приемник данных
В качестве источника выбираем Google BigQuery, в качестве приемника - хранилище S3, в качестве набора данных - "Стандартная выгрузка данных".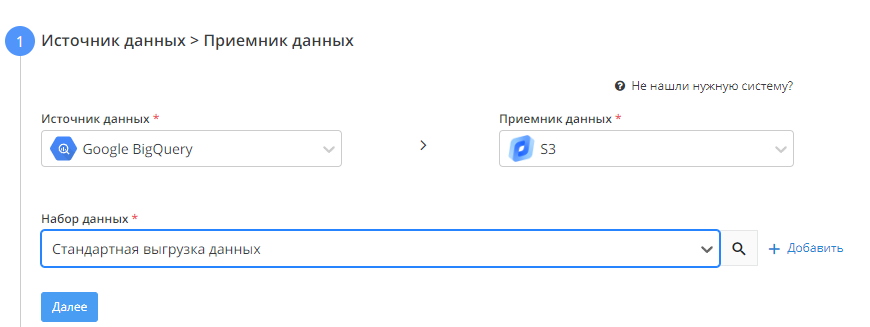
Настройка источника данных
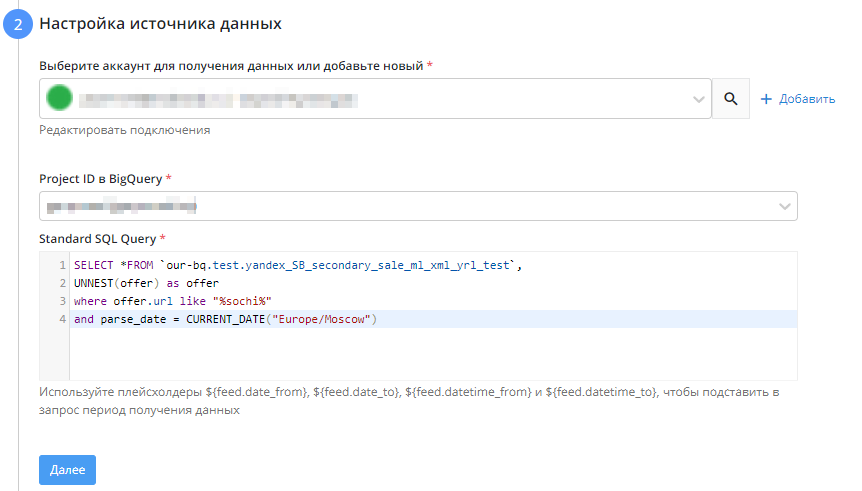
- Выбираем аккаунт для получения данных
- Выбираем проект, из которого будем брать данные
- Прописываем SQL запроc
 Используйте плейсхолдеры ${feed.date_from}, ${feed.date_to}, ${feed.datetime_from} и ${feed.datetime_to}, чтобы подставить в запрос период получения данных. Например,
Используйте плейсхолдеры ${feed.date_from}, ${feed.date_to}, ${feed.datetime_from} и ${feed.datetime_to}, чтобы подставить в запрос период получения данных. Например, WHEREdateBETWEEN'${feed.date_from}'AND'${feed.date_to}'
Настройка приемника данных
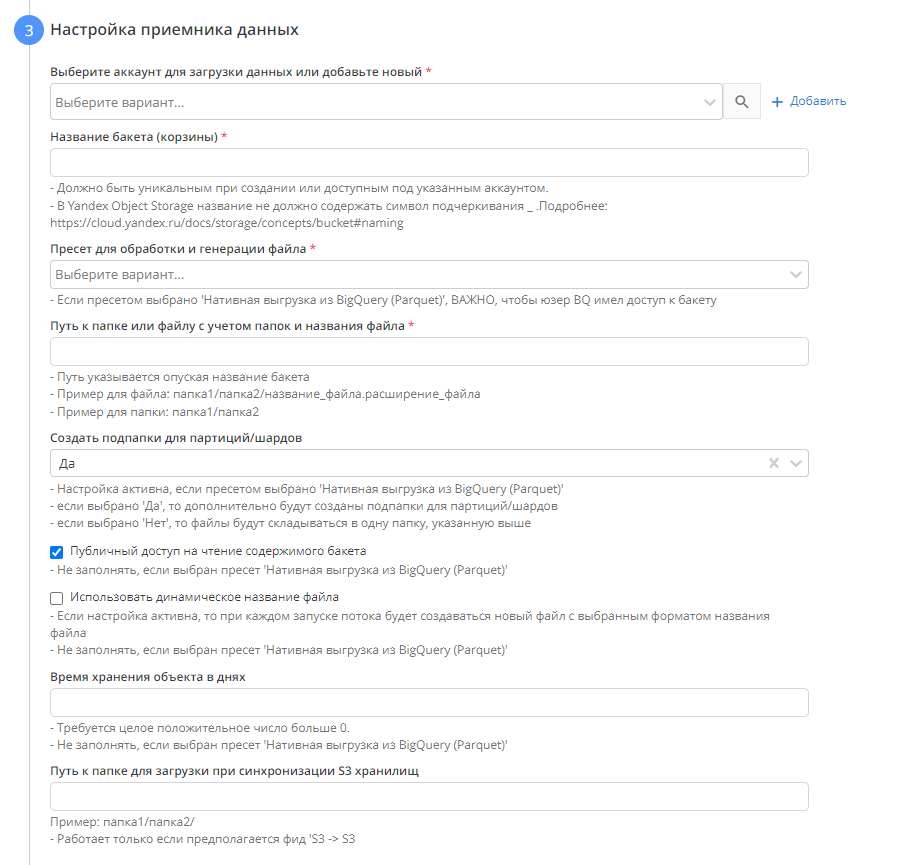
- Выбираем аккаунт для загрузки данных
- Название бакета. Инструкция по неймингу бакета для GCS: https://cloud.google.com/storage/docs/buckets#naming, для Yandex Object Storage - https://cloud.yandex.ru/docs/storage/concepts/bucket#naming
- Выбираем пресет для успешной генерации YRL (YRL_Realty_Feed_XML_Structure). Используем его для генерации из YRL в YRL.
- Путь к файлу
- Создавать ли подпапки для партиций. При использовании опции в указанной папке будут созданы подпапки, разбитые по датам.
- "Использовать динамическое название файла". При включенной опции каждый запуск потока будет создавать в приемнике новый файл по выбранному шаблону

- Время хранения в днях.
4. Общие настройки
На этом этапе вам необходимо изменить название потока если необходимо. Название потока генерируется автоматически.
...