Garpun Feeds через свой сервис фиды (потоки) может выгружать файлы из Google Cloud в Я.Облако (S3). S3 работает как файлохранилище. Про его настройки можно отдельно почитать в документации самого сервиса: https://cloud.yandex.ru/docs/storage/quickstart
S3 помечается отдельно, так как имеется ввиду технология облачного хранилища Amazon S3, на базе которого можно организовать собственное хранилище в Я.Облако
Особенность сервиса заключается в том, что по сути это файло-хранилище, поэтому потоки данных в ходе работы будут формировать файлы и помещать их в облако, указанное пользователем.
Перед началом работы нужно добавить подключение к Облаку (если оно уже организовано, переходим к созданию потока)
Предварительно авторизовавшись в системе Garpun переходим в раздел "Подключения"(ссылка), выбираем S3, нажимаем "+подключение". Также, для добавления можно использовать кнопку ![]() на втором шаге настройки потока.
на втором шаге настройки потока.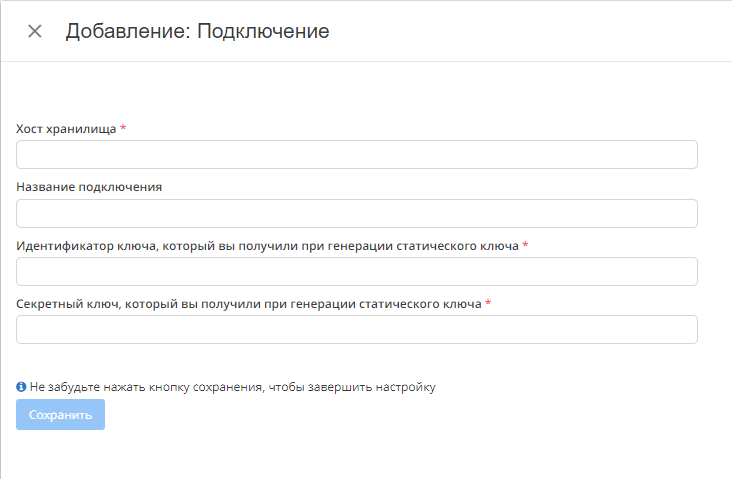
Для работы рекомендуем пользоваться инструкцией https://cloud.yandex.ru/docs/storage/operations/
Что нужно вводить на этапе подключения:
Хост хранилища - расположение хранилища в сети, его настраиваете при работе с хранилищем и хостингом
Название подключения - то, как будет называться наше подключение.
Идентификатор ключа - ID ключа шифрования в вашем хранилище. Не сам ключ а именно ID, система по этому ID будет отправлять запрос на работу с данными.
Секретный ключ - Один из ключей шифрования, который генерируется при помощи статического ключа. Нужен для обращения к данным.
Идентификатор ключа и Секретный ключ вы получаете при генерации статического ключа:

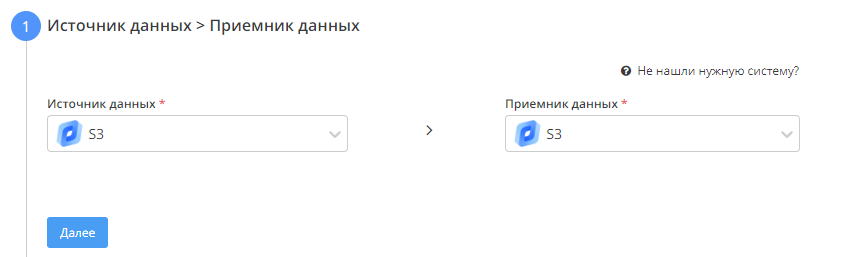
- Выбираем источник и приемник данных, а так же набор данных:
- Настраиваем Источник данных
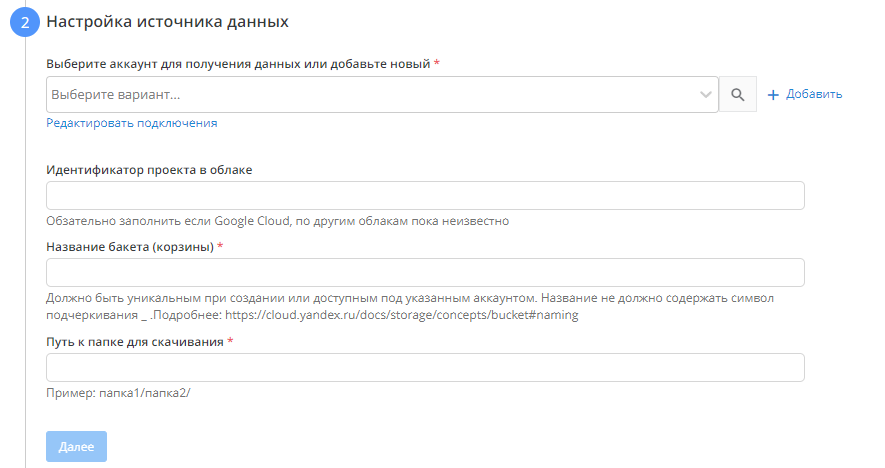
Выбираем необходимый аккаунт для выгрузки данных, либо добавляем новый.
Идентификатор проекта в облаке - необязательное поле, но для использовании в связке с Google Cloud - обязательное.
Название бакета и путь к папке указывается обязательно.
- Настраиваем Приемник данных.
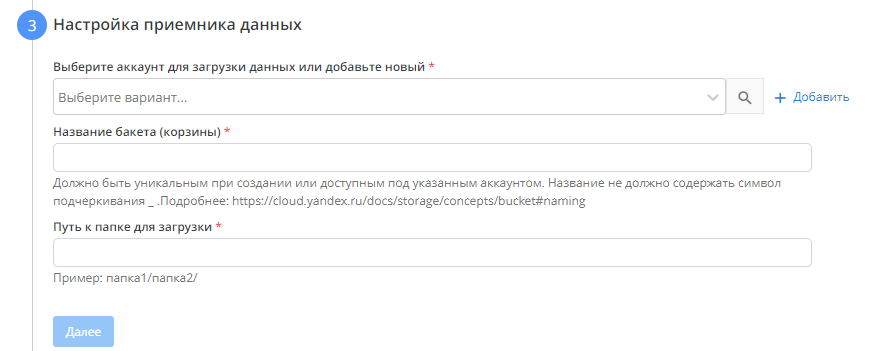
Выбираем необходимый аккаунт для выгрузки данных, либо добавляем новый.
Название бакета и путь к папке указываются обязательно.
- Общие настройки
На этом этапе вам необходимо изменить название потока если необходимо. Название потока генерируется автоматически.
Выбрать период сбора при автоматическом перезапуске. По умолчанию устанавливается "на основе внутренних правил", что означает, что пересбор потока будет происходить за последнии 30 дней.
Установить расписание
Нажать "Готово"