Генерация кампаний - часть системы Garpun, помогающая автоматизировать процесс создания контекстных кампаний. Пользователь создает алгоритм генерации и подключает источник данных о товарах и категориях. На основе этой информации система генерирует контекстные объявления и ключевые слова. Алгоритм - это набор правил обработки источника данных, а также шаблоны ключевых слов и объявлений. Создание алгоритма подразумевает последовательное заполнение четырёх блоков.
Начальный этап
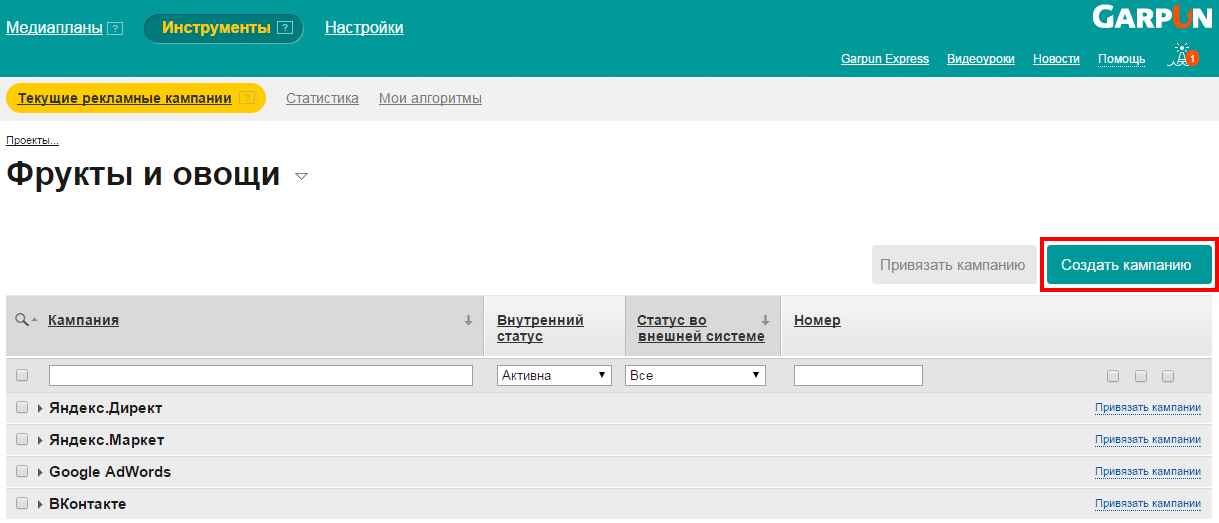
Чтобы создать алгоритм автоматизированной рекламной кампании, необходимо перейти в нужный проект и нажать на кнопку "Создать кампанию"
 Название алгоритма
Название алгоритма
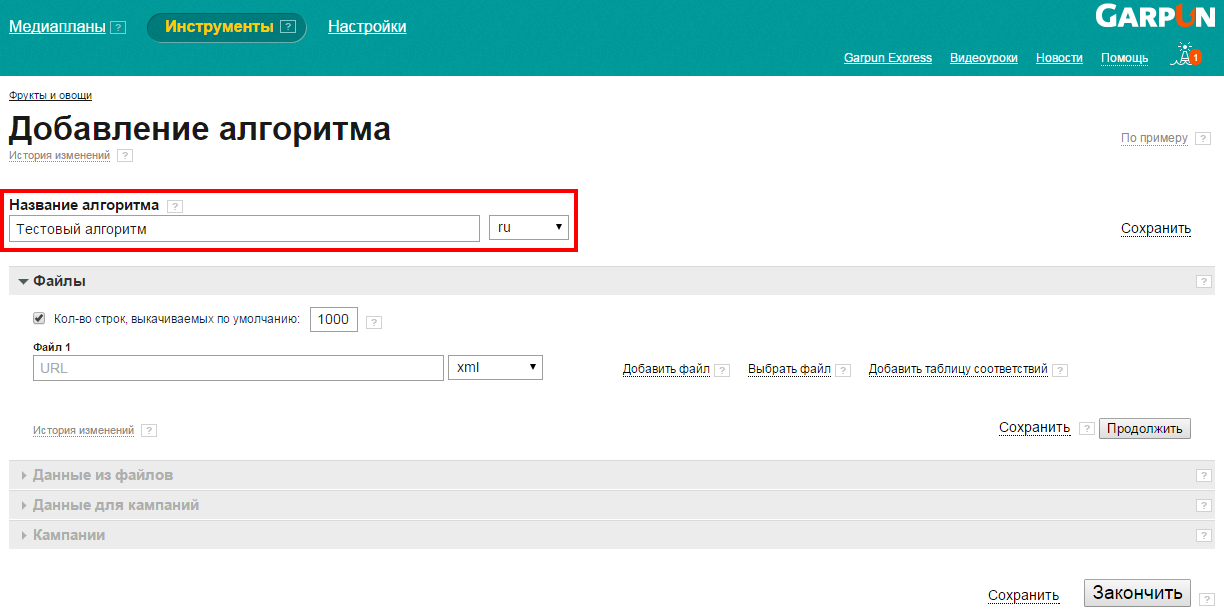
Используйте удобные названия для однозначного определения алгоритма, чтобы в дальнейшем не возникало трудностей в работе с системой.
Кнопка "Сохранить" в блоках
По нажатию на кнопку сохраняются изменения в блоке.
Кнопка "Продолжить" в блоках
По нажатию на кнопку сохраняются изменения блоке и разворачивается следующий блок для заполнения.
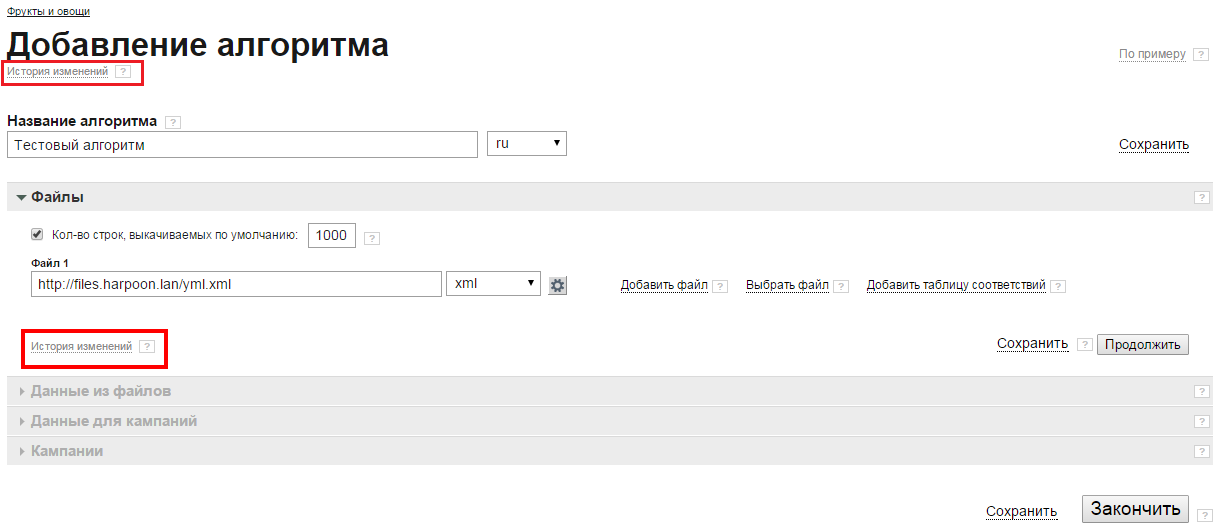
История изменений
По нажатию на ссылку откроется окно с записанной историей изменений, внесенных в алгоритм. Ссылка на историю изменений приведена в верхней части страницы и дублируется внутри блоков.
По кнопке "Откатить" будут применены настройки, актуальные на указанную дату, то есть на момент последнего нажатия кнопок "Cохранить" или "Продолжить".
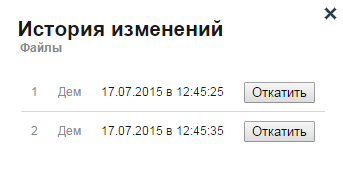
По примеру для всего алгоритма

Из выпадающего списка выбирается ранее созданный алгоритм, настройки которого будут применены к создаваемому алгоритму. Это удобно, если ваш новый алгоритм будет во многом повторять уже имеющийся или же ваш фид данных стандартизирован для загрузки информации о товарах и услугах на популярные ресурсы, такие как Яндекс.Авто, Яндекс.Недвижимость, IRR.Недвижимость и другие.
Данные алгоритма, выбранного по примеру, загружаются в конструктор автоматически по нажатию на кнопку "Применить" и не требуют перезагрузки страницы.
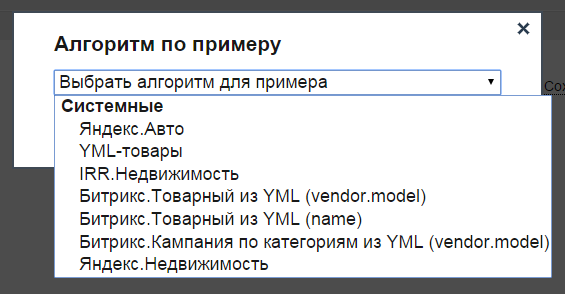
Блок "Файлы"
В блоке указываются источники данных, которые будут использоваться на следующих этапах. В поле вводим URL-ссылку на имеющийся файл-источник. Он может быть форматов XML, YML или CSV.
Файл-источник - файл выгрузки полной информации о товарах/услугах/предложениях вашего интернет-магазина. Файл формата YML используется для размещения информации в базе данных Яндекс.Маркета. По сути, это разновидность XML-файла. Система Garpun принимает также файлы форматов CSV и любые XML.
Если Вы не знаете где взять файл подобных форматов - обратитесь к вашему веб-мастеру. Если у вас нет возможности сформировать фид данных, попробуйте создать контекстную кампанию на основе контента сайта (Google DSA). Эта возможность доступна в легком интерфейсе Гарпуна - системе Garpun Express. Работа в Garpun Express доступна с вашим текущим аккаунтом в системе Garpun.
По кнопке "Сохранить" внесённые данные сохраняются. По кнопке "Продолжить" внесённые данные сохраняются, затем система автоматически перенаправляет пользователя ко второму шагу (к блоку "Данные из файлов").
При необходимости, добавляем ещё файлы-источники.
Добавить файл. По нажатию на ссылку появляется поле для ввода ещё одной URL-ссылки файла-источника.
Выбрать файл. По нажатию на ссылку пользователь выбирает уже имеющийся файл на ПК для его загрузки в систему Garpun. При наведении курсора на поле появляется кнопка  , по нажатию на которую поле удаляется.
, по нажатию на которую поле удаляется.
Максимально разрешенное количество файлов источников - 4.
Максимальный размер файла-источника не может превышать 35 Mb.
Количество строк, выкачиваемых по умолчанию из фида, - 1000. Для того чтобы снять ограничение для всех файлов, необходимо кликнуть на групповой чекбокс.
Если необходимо сменить ограничение только для определенного файла, то такая возможность предусмотрена в форме настроек XML-файла.
Настройки файла-источника осуществляются в отдельной форме, вызываемой нажатием кнопки  у поля ввода URL-адреса файла-источника. Настройки различаются в зависимости от типа выбранного источника.
у поля ввода URL-адреса файла-источника. Настройки различаются в зависимости от типа выбранного источника.
Для файлов *.xml:
- Количество строк, выкачиваемых по умолчанию - 1000. Ограничение действует только на текущий файл. Для того, чтобы снять ограничение для всех файлов, необходимо кликнуть на групповой чекбокс "Количество строк, выкачиваемых по умолчанию", который находится в самом начале блока "Файлы".
- Авторизационные данные: логин и пароль. Указывается, если файл защищен HTTP-авторизацией. Если Вы не знаете логин и пароль для авторизации, обратитесь к своему веб-мастеру.
Чекбокс "Применить ко всем файлам" - при постановке чекбокса введённые логин и пароль будут использоваться для всех файлов-источников, прикрепленных пользователем. Это избавляет от необходимости прохождения авторизации для каждого прикреплённого файла.
- Тип кодировки файла источника. Тип кодировки файла-источника по умолчанию UTF-8, однако, существует возможность изменить кодировку на Windows-1251. Кроме того, доступно автоматическое распознавание кодировки. Если в результатах генерации некорректно отображается информация, попробуйте сменить кодировку файла-источника.
Для файлов *.csv:
- Разделители. Символ, который используется для разделения значений в файле-источнике (обычно используется запятая).
- Огр.строк. Символ, который используется в качестве ограничителя строки в файле CSV (указывает на момент перехода на новую строку).
- Чекбокс "В файле имеется шапка". Установите чекбокс, если у файла CSV имеется шапка (заголовок, наименование).
Блок "Данные из файлов"
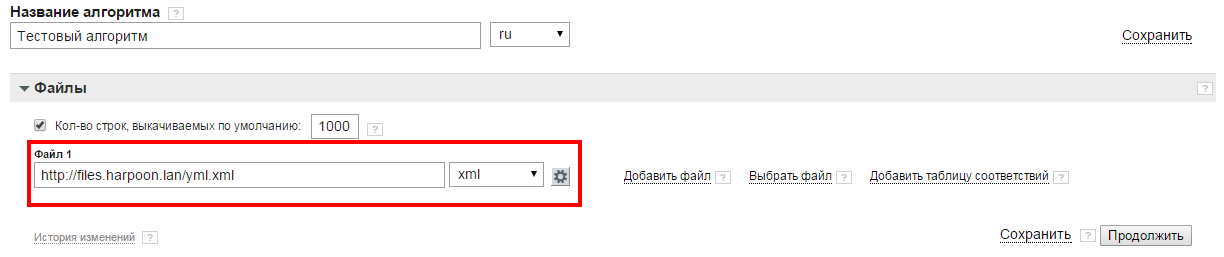
Если ваш фид имеет формат YML, то при переходе к блоку "Данные из файлов", система выдаст уведомление об обнаружении YML-файла и предложит применить к нему стандартный системный алгоритм. Это поможет сократить время настройки алгоритма и быстрее запустить кампанию. Нажмите на кнопку "Применить", если хотите загрузить настройки стандартного алгоритма. Если есть необходимость самостоятельной настройки, либо вид фида определён неверно,нажмите на кнопку "Отмена".
Блок "Данные из файлов" разделен на две части: "Файлы" и "Ожидаем данные" (после выбора элементов будет называться "Данные из файлов").
Файлы. В этой части блока в виде раскрывающегося списка отображается структура XML-файла. По клику на элемент раскрывается его содержимое.
Элементы выбираются кликом по чекбоксу слева. Для выбора доступны только те элементы, у которых нет вложенных тегов. Выбранные элементы сразу же появляются в правой части блока "Ожидаем данные". Выберите на этом этапе все те элементы, которые пригодятся вам для создания шаблонов объявлений и ключевых слов.

Необходимо выбрать ключевой элемент - элемент таблицы, который уникально идентифицирует все записи в файле (уникальные, неповторяющиеся значения, например, нумерация или id).
Ключевой элемент назначается чекбоксом слева от его названия и нажатием на кнопку  после отметки чекбокса. Ключевым может быть выбран только один элемент. Если напротив отмеченного чекбоксом элемента кнопка неактивна, значит другой элемент ранее уже был назначен ключевым. Часто ключевым элементом выбирают offer id или близкое к нему по смыслу поле.
после отметки чекбокса. Ключевым может быть выбран только один элемент. Если напротив отмеченного чекбоксом элемента кнопка неактивна, значит другой элемент ранее уже был назначен ключевым. Часто ключевым элементом выбирают offer id или близкое к нему по смыслу поле.

Если вы забыли, какие данные в себе заключает какой-то из элементов, вы можете посмотреть его содержимое в отдельно появляющемся окне, нажав на кнопку напротив интересующего элемента.
Ожидаем данные. В этой части блока появляются выбранные ранее (в части "Файлы") элементы файла-источника. Здесь же, при необходимости, устанавливается связь с другими элементами файла-источника или элементами другого фида по кнопке . Наличие связей между полями позволяет легко ссылаться упрощенным данным на полные данные (например, связав category id с элементом category, система по id распознает наименование самой категории; также с помощью связи можно подключить к элементу словарь синонимов).
Блок "Данные для кампаний"
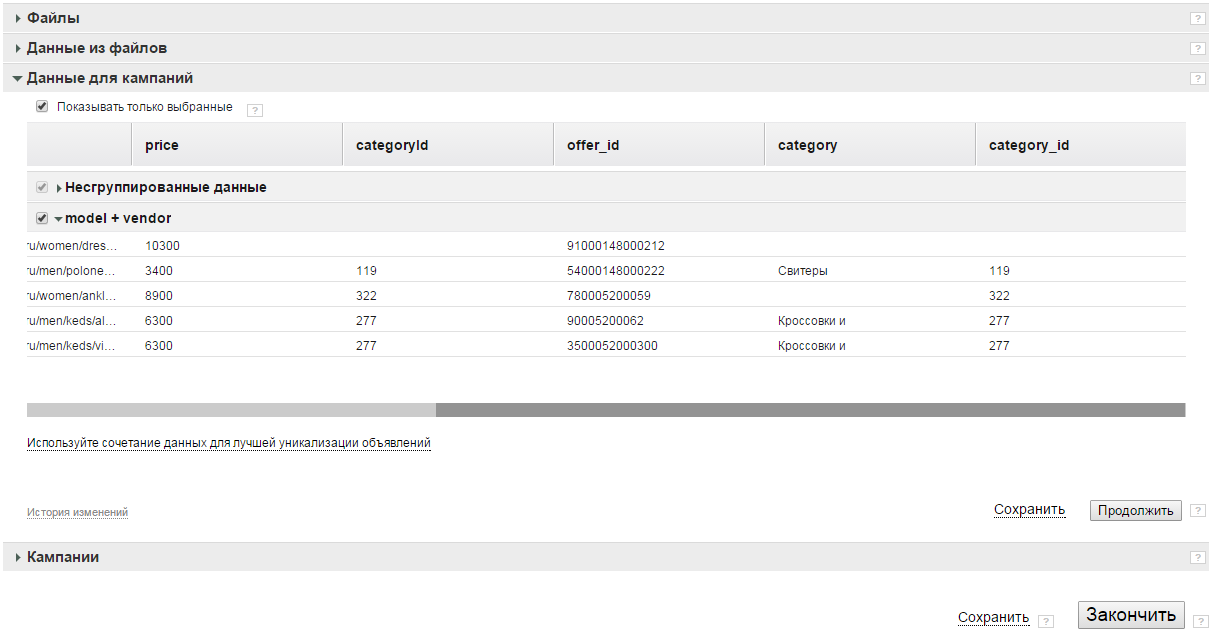
В этом блоке мы видим нормализованные данные. Это значит, что выбранные элементы, а также связи между ними преобразованы в плоскую таблицу. В боксах представлен каждый вариант группировки данных из ранее выбранных элементов.
Для просмотра примеров нужно раскрыть бокс, кликнув по его названию. По-умолчанию выбран бокс "Несгруппированные данные", и он не может служить в качестве источника данных при дальнейшем создании шаблонов объявлений и ключевых слов.
На данном этапе происходит группировка, уникализация и очистка данных. Уникализация будет произведена по выбранному сочетанию значений элементов. В дальнейшем для каждой строки будет создано отдельное объявление. Например, для бокса offer_id будет создано по объявлению на каждый уникальный offer_id, присутствующий в источнике данных. В случае выбора vendor + model будет создано по объявлению на каждую уникальную связку vendor + model. Все неуникальные значения элемента в данном случае будут объединены в массив и помещены в одну общую ячейку.
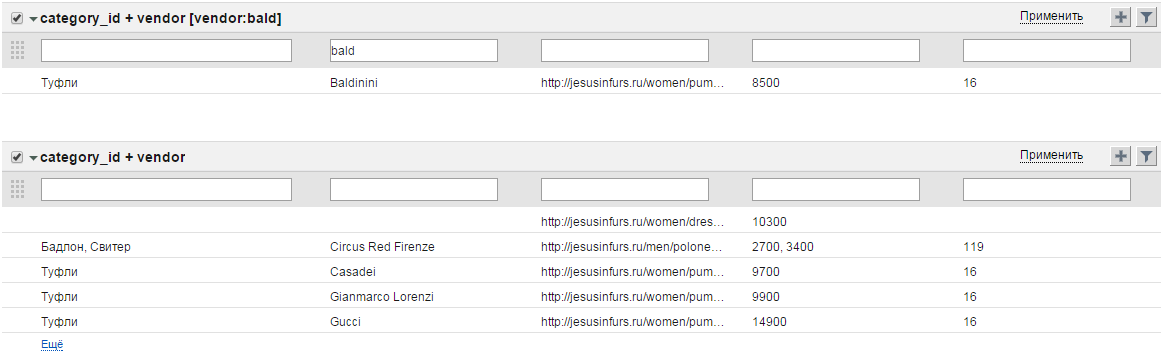
Пример
На скриншоте показаны два бокса - Model и Model + vendor. Обратим внимание на кеды. В боксе Model уникализация происходит по модели (виду) одежды. Поэтому кеды как вид одежды встречается единожды. Так как магазин продает кеды двух марок, в поле Vendor эти марки будут заключены в одну ячейку и перечислены через запятую. Поскольку цена кед и их категория одинакова, в полях Price и categoryId содержится по одному значению. В поле offer_url также представлены две ссылки, но поскольку ширина поля ограничена, мы видим только начало одной из них. Чтобы увидеть полное содержание ячейки, подведите к ней курсор и подождите около секунды. В боксе Model + Vendor уникализация проверяется по двум полям, поэтому хотя и название вида одежды (кеды) повторяется, в связке с маркой эти значения уникальны, а потому будут разнесены по отдельным строкам.
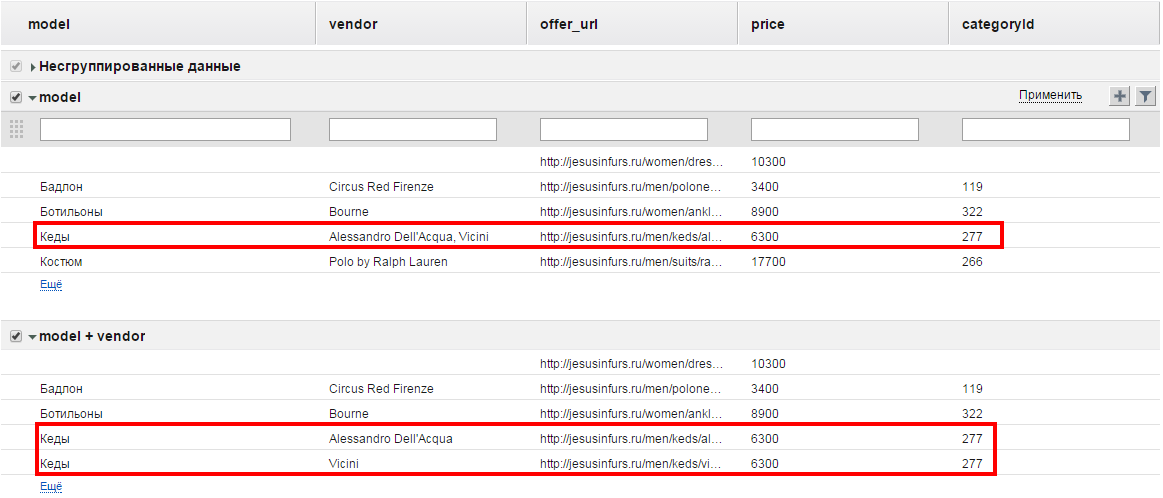
Показать только выбранные. При включенном чекбоксе будут отображаться только выбранные боксы. При снятом выделении будут отображаться все варианты.
Вы можете добавить собственный бокс (вариант группировки данных). Для этого нажмите на ссылку "Используйте сочетание данных для лучшей уникализации объявлений".
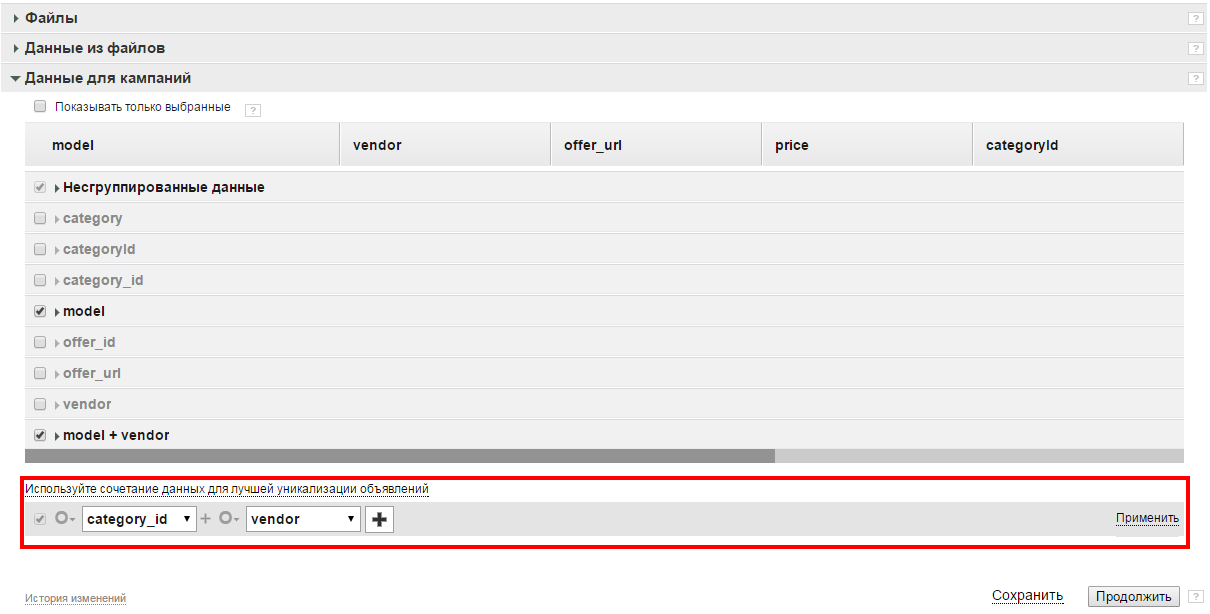
В появившемся конструкторе выберите нужное вам сочетание полей, по которым будет происходить уникализация. Чтобы добавить в связку полей еще одно поле, нажмите на кнопку  . По окончании не забудьте нажать на ссылку "Применить".
. По окончании не забудьте нажать на ссылку "Применить".
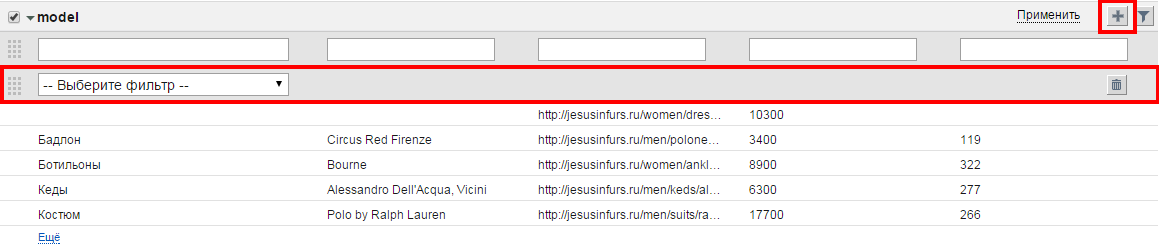
Напротив названия каждого бокса есть кнопки, позволяющие выполнять ряд действий над этим боксом.
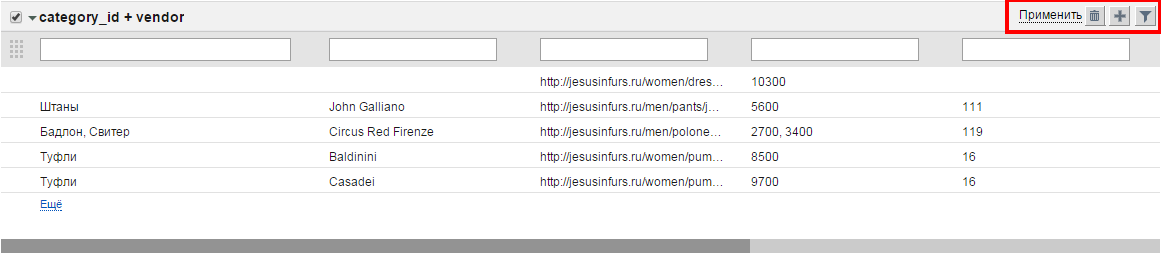
- - удалить бокс
- - добавить фильтр
 - показать / скрыть фильтры
- показать / скрыть фильтры
Фильтры в боксах бывают двух видов:
- Текстовые фильтры над полями. С их помощью можно выбрать только те строки, по которым значения ячеек в определенных полях содержат введенный в фильтр текст. Для отображения фильтра нажмите . Чтобы отфильтровать строки, введите текст в фильтр и нажмите ссылку "Применить". Отфильтрованные строки будут выделены в отдельный бокс. При этом исходный бокс также останется выбранным. Возможно использовать символ " | " (вертикальная черта) как логический оператор ИЛИ; также возможно использование символа " (двойная кавычка) для указания точного соответствия.
- Помимо текстового фильтра существуют и другие. Они позволяют различным образом модифицировать значения таблицы, приводя их к желаемому виду. Для добавления фильтра нажмите на кнопку напротив названия бокса.
На текущий момент представлены следующие фильтры:
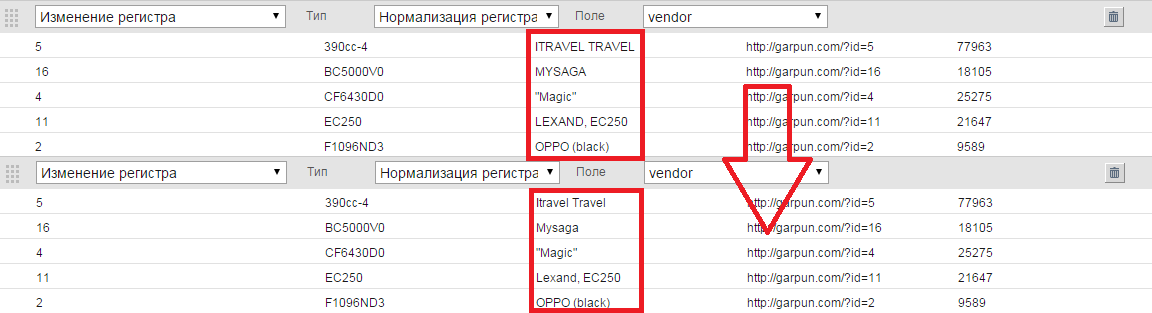
- Изменение регистра. Фильтр позволяет изменить или нормализовать регистр в выбранном поле. Если данные в базе представлены с нарушением регистра, то это исправляется с помощью данного фильтра. Есть несколько типов этого фильтра.
- все строчные - после применения фильтра текст в ячейках выбранного поля будет написан строчными буквами;
- ВСЕ ПРОПИСНЫЕ - перевод текста в ячейках выбранного поля в верхний регистр;
- Начинать С Прописных - каждое слово (включая предлоги, артикли и междометия) будет начинаться с прописной буквы;
- Как в предложении - каждое новое слово, открывающее предложение, будет начинаться с прописной буквы;
- Нормализация регистра - модифицирует каждое слово в строке по алгоритму: если слово длиннее 4 символов и если в нем нет цифр и букв в нижнем регистре, то первая буква становится прописной, остальные в нижний регистр; этот тип фильтра полезен, если необходимо привести регистр к нормальному виду, но при этом не затронуть аббревиатуры.
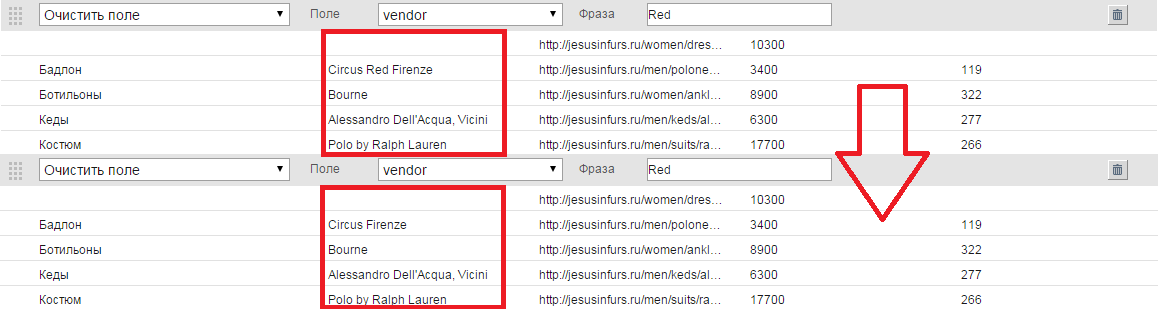
- Очистить поле. Фильтр удаляет введённые символы (числа, буквы, фразы) в выбранном поле. Выбираем поле, для которого фильтр будет применён и вводим то, что подлежит удалению - любая фраза, буква, символ, цифра, то есть любая лишняя информация, которая не нужна для генерации кампаний.
- YML очистка офферов.
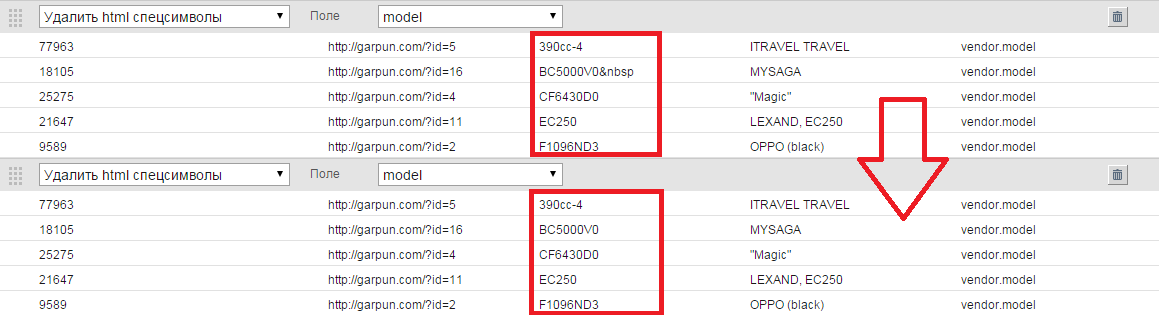
- Удалить html-спецсимволы.Фильтр из выбранного поля удаляет спецсимволы html-кода (например,   и др.). При экспорте из базы данных некоторые спецсимволы из html-разметки могут попасть в экспортируемые данные. При применении фильтра выбираем поле, в котором присутствуют лишние символы.
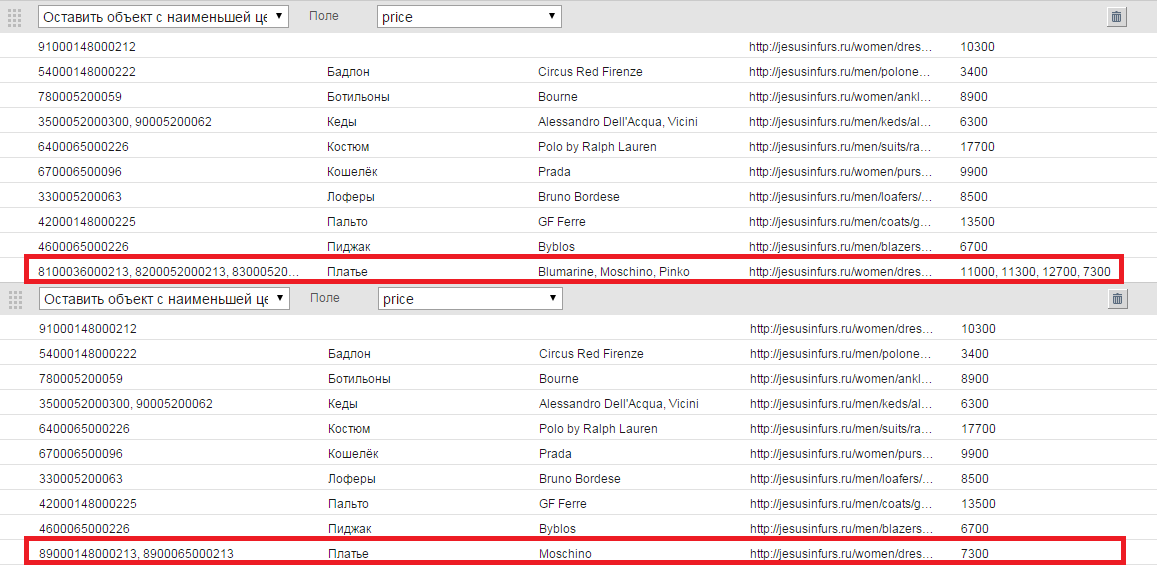
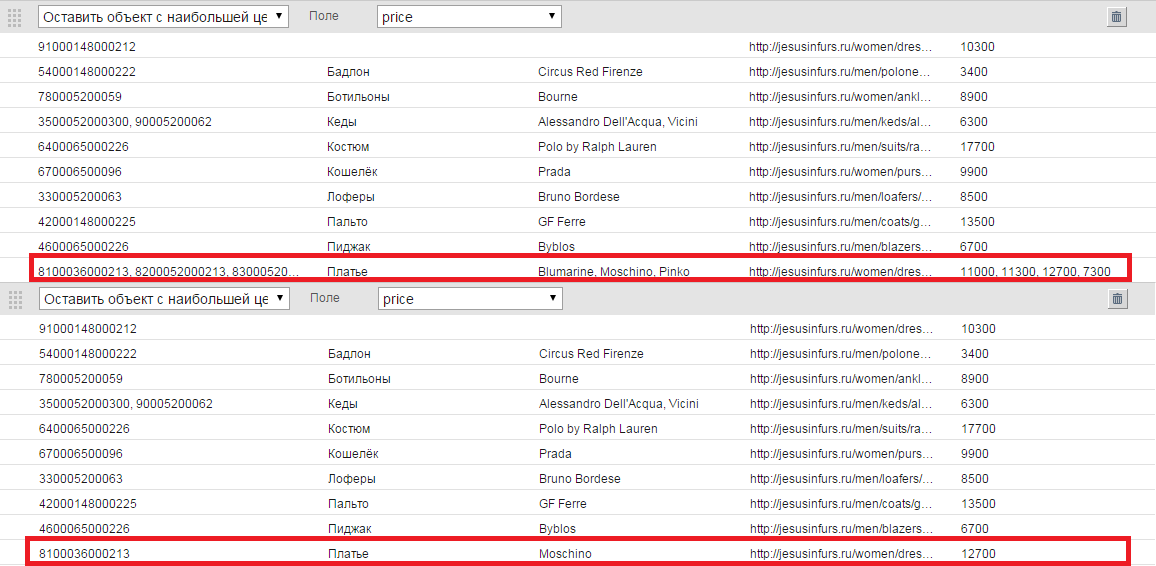
- Оставить объект с наибольшей ценой. Фильтр применяется во избежание генерации объявлений с несколькими ценами, если произошло объединение нескольких строчек в массив .Выбираем поле, в котором содержится информация о цене товара.
- Оставить объект с наименьшей ценой. Фильтр применяется во избежание генерации объявлений с несколькими ценами.
Выбираем поле, в котором содержится информация о цене товара.