Garpun Feeds может выгружать файлы из Google BigQuery в S3.
S3 — сервис хранения неструктурированных данных. Внутри можно хранить все что захотим, но в основном используется как файловое хранилище. Каждый файл представлен в виде объекта, сами же объекты лежал в бакетах.
Про его настройки можно отдельно почитать в документации самого сервиса: https://cloud.google.com/storage/docs/introduction
Перед началом работы нужно добавить подключения к BQ и S3(если оно уже организовано, переходим к этапу созданию потока):
Авторизовавшись в системе Garpun переходим в раздел "Подключения"(ссылка), выбираем S3, нажимаем "+подключение".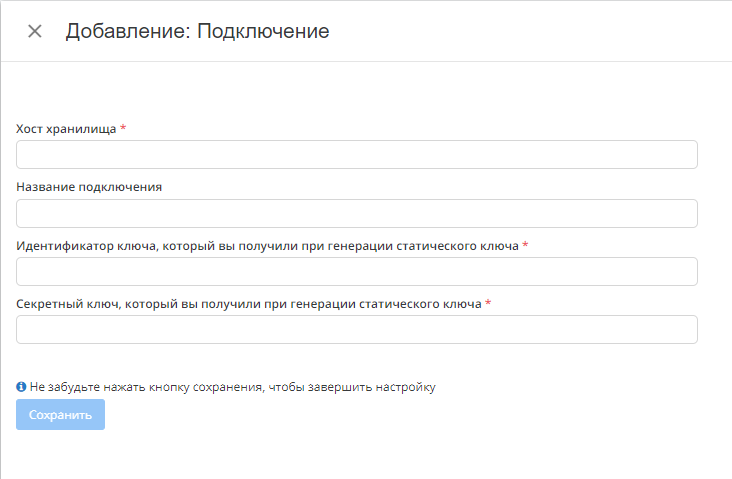
Хост хранилища - расположение хранилища в сети, его настраиваете при работе с хранилищем и хостингом
Название подключения - то, как будет называться наше подключение.
Идентификатор ключа - ID ключа шифрования в вашем хранилище. Не сам ключ а именно ID, система по этому ID будет отправлять запрос на работу с данными.
Секретный ключ - Один из ключей шифрования, который генерируется при помощи статического ключа. Нужен для обращения к данным.
Авторизовавшись в системе Garpun переходим в раздел "Подключения"(ссылка), Выбираем Google BigQuery, нажимаем "+подключение".
- Нажимаем кнопку подключить
- Выбираем необходимый аккаунт
- Нажимаем "Разрешить"
- Источник данных > Приемник данных
В качестве источника выбираем Google BigQuery, в качестве приемника - хранилище S3, в качестве набора данных - "Стандартная выгрузка данных".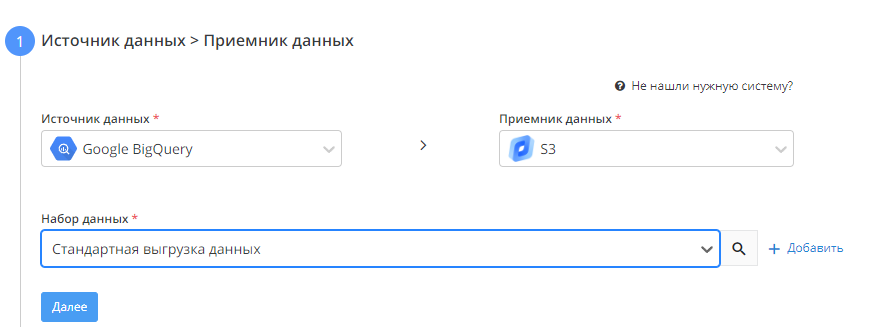
- Настройка источника данных
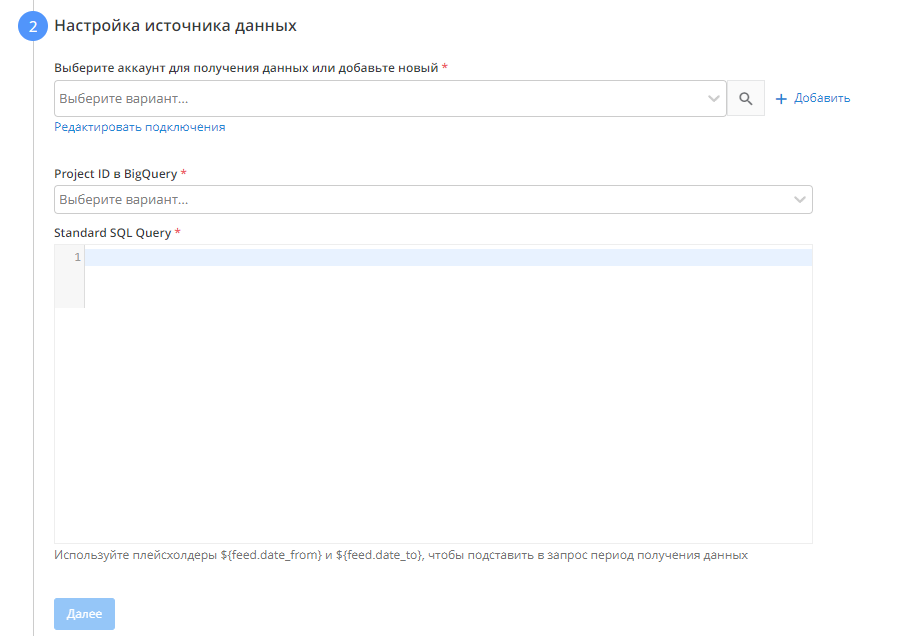
- Выбираем аккаунт для получения данных
- Выбираем проект, из которого будем брать данные
- Прописываем SQL запроc
 Используйте плейсхолдеры ${feed.date_from}, ${feed.date_to}, ${feed.datetime_from} и ${feed.datetime_to}, чтобы подставить в запрос период получения данных. Например,
Используйте плейсхолдеры ${feed.date_from}, ${feed.date_to}, ${feed.datetime_from} и ${feed.datetime_to}, чтобы подставить в запрос период получения данных. Например, WHEREdateBETWEEN'${feed.date_from}'AND'${feed.date_to}'
- Настройка приемника данных
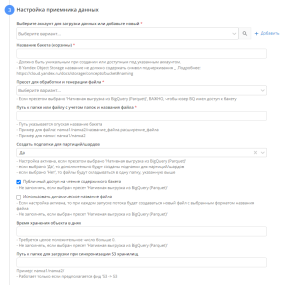
- Выбираем аккаунт для загрузки данных
- Название бакета. Инструкция по неймингу бакета для GCS: https://cloud.google.com/storage/docs/buckets#naming, для Yandex Object Storage - https://cloud.yandex.ru/docs/storage/concepts/bucket#naming
- Пресет для обработки и генерации файла. Если пресетом выбрано 'Нативная выгрузка из BigQuery (Parquet)', важно, чтобы юзер BQ имел доступ к бакету
- Путь к файлу
- Создавать ли подпапки для партиций. При использовании опции в указанной папке будут созданы подпапки, разбитые по датам.
- "Использовать динамическое название файла". При включенной опции каждый запуск потока будет создавать в приемнике новый файл по выбранному шаблону

- Время хранения в днях.
4. Общие настройки
На этом этапе вам необходимо изменить название потока если необходимо. Название потока генерируется автоматически.
Выбрать период сбора при автоматическом перезапуске. По умолчанию устанавливается "на основе внутренних правил", что означает, что пересбор потока будет происходить за последнии 30 дней.
Установить расписание
Нажать "Готово"