Общая информация
Garpun feeds - это инструмент получения данных из различных источников (GA, Google Ads, Яндекс Директ, VK, FB, MyTarget, AMO CRM и т.д.) и загрузки в Google BigQuery. С помощью Garpun Feeds вы можете настроить загрузку данных из систем статистики, аналитических систем, данных из СRM системы в единое хранилище и использовать BI системы для визуализации отчетности (Google Data Studio, Power BI, Tableo и др).
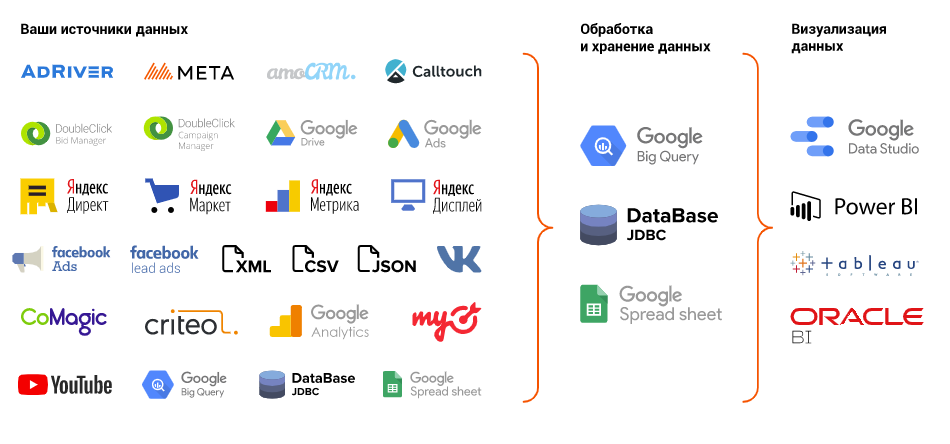
Список систем, для которых доступна загрузка данных BQ, Googlespreadsheet, GA
| Откудa | Куда | |||
| Системы | BQ | Googlespreadsheet | GA | Почта |
|---|---|---|---|---|
| AMO CRM | + | + | ||
| Apple Search | + | + | ||
| AppsFlyer | + | + | ||
Bitrix24
| + | + | ||
| Chat2Desk | + | + | ||
| CallTouch | + | + | ||
| Comagic | + | + | ||
| Criteo | + | + | ||
DBM
| + | + | ||
DCM
| + | + | ||
| Facebook Ads | + | + | + | |
| Facebook Leads | + | + | + | |
| Google Ads | + | + | ||
| Google Analytics | + | |||
| Mailchimp | + | + | ||
| MyTarget | + | + | + | + |
| My Target Leads | + | + | + | |
| RTB House | + | + | ||
| TikTok | + | + | + | |
Track Ad | + | + | ||
| Vk Ads | + | + | + | |
| Vk Leads | + | + | + | |
| Yandex AppMetrica | + | + | ||
| Yandex Direct | + | + | + | |
| Yandex Display | + | + | ||
| Yandex Market Partner | + | + | ||
| Yandex Metrica | + | |||
| Database | + | |||
| AdRiver | + | |||
Регистрация в системе
Прочитать про регистрацию вход в Garpun Feeds вы можете по ссылке: Регистрация в Garpun, Garpun Feeds.
Переход в систему
Перейти в систему Garрun Feeds можно по прямой ссылке: https://feeds.garpun.com/
Инструменты
На главной странице странице располагаются информация о потоках данных и наборах данных.
Потоки данных
На данной странице находятся уже созданные вами потоки .Поток - это алгоритм, с помощью которого происходит выгрузка данных из рекламных систем в Google BQ.
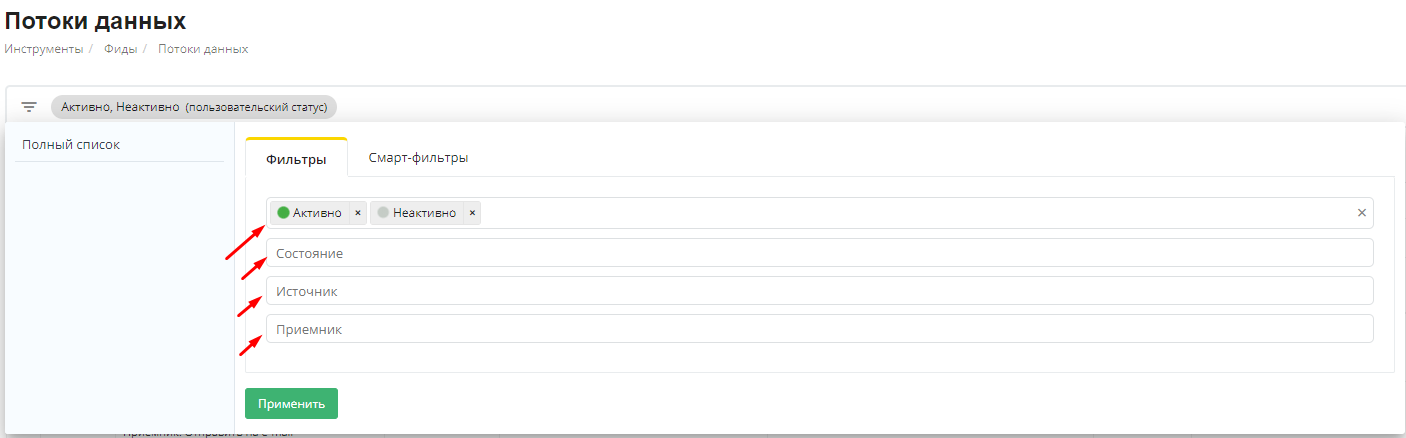
Облегчить поиск того или иного потока можно с помощью фильтров:
- -по статусу потока (Активно/Неактивно)
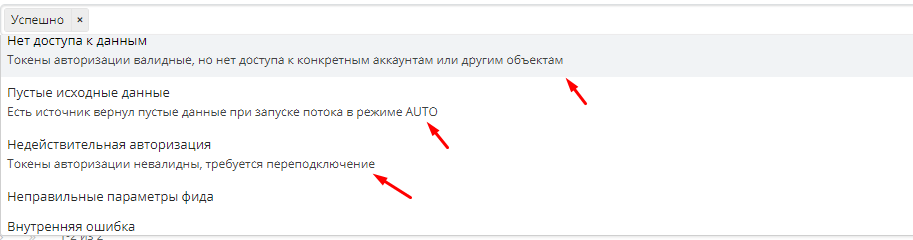
- -по состоянию (В ожидании/В обработке/Успешно/Обработан с замечаниями/Нет доступа к данным/Недействительная авторизация/Неправильные параметры фида/Внутренняя ошибка)
![]() О том, что означают те или иные состояния потока дано объяснение ниже
О том, что означают те или иные состояния потока дано объяснение ниже
- по источнику ( amoCRM/Calltouch/Comagic/Criteo REST/CSV/DBM/Facebook Ads/Google Ads/XML/Google BigQuery и тд)***
- пол приемнику (Google BigQuery/BigQueryPartitioned/Google Analytics/Yandex Cloud Storage/Ничего не делать/Отправить на e-mail)
*** Все источники данных вы можете найти в https://feeds.garpun.com/
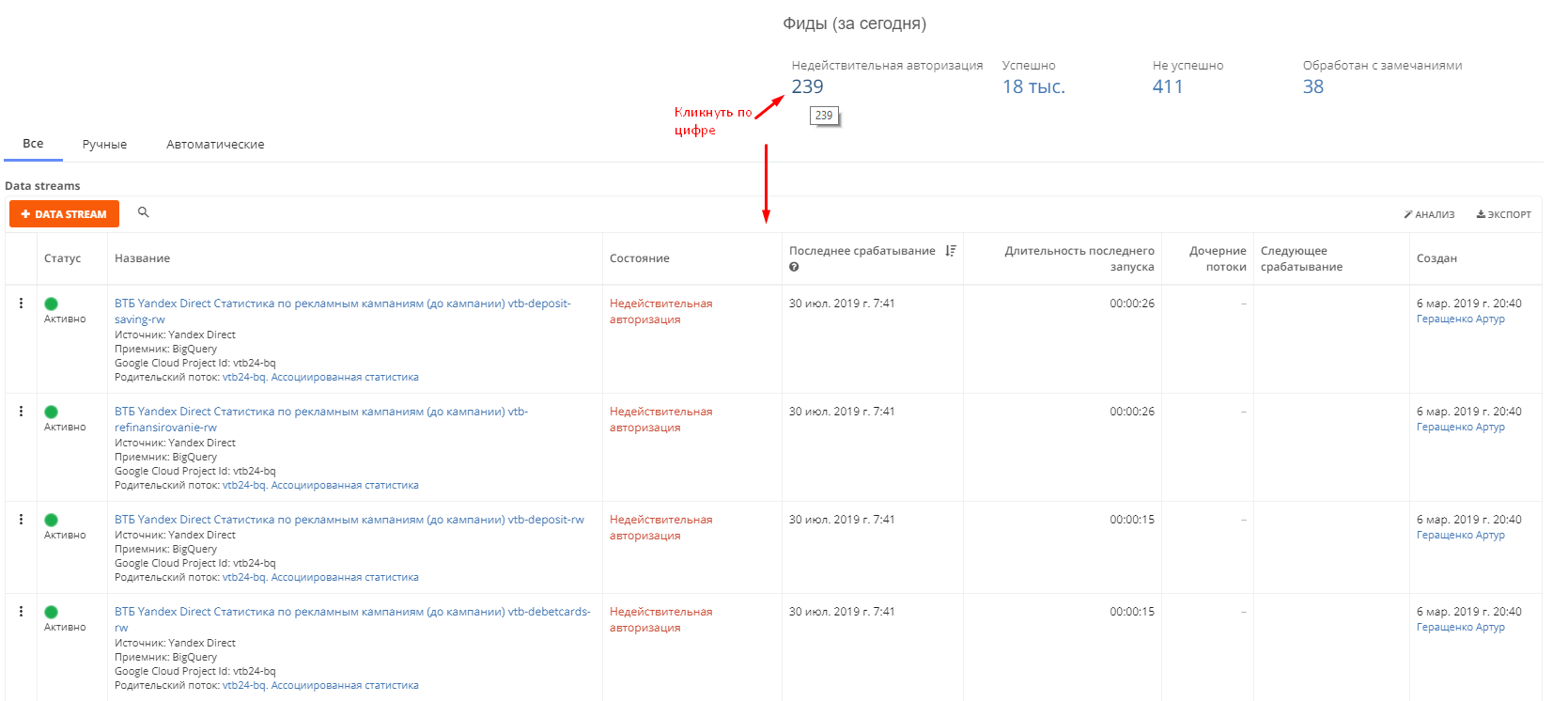
Справа над потоками располагается дашборд со статистикой за сегодняшний день.Она показывается кол-во потоков, которые завершились со статусом "Успешно" и "Не успешно", по скольким была "Недействительная авторизация" (вам нужно переподключить аккаунт) и сколько было "Обработано с замечаниями". При клике на любую из цифр открывается полный список потоков с тем или иным состоянием.
Под фильтрами мы видим вкладки с помощью которых можно фильтровать потоки на ![]() . В данный момент клиентам Garpun Feeds доступно только создание ручных потоков, но в будущем будут доступны и автопотоки, то есть потоки, которые будут автоматически создаваться при привязке аккаунтов рекламных систем к Garpun Feeds.
. В данный момент клиентам Garpun Feeds доступно только создание ручных потоков, но в будущем будут доступны и автопотоки, то есть потоки, которые будут автоматически создаваться при привязке аккаунтов рекламных систем к Garpun Feeds.
Для создания потока вам нужно нажать на кнопку  . При создания потока данных вам нужно пройтись по всем шагам, после каждого шага вам нужно нажимать кнопку
. При создания потока данных вам нужно пройтись по всем шагам, после каждого шага вам нужно нажимать кнопку  . Она становится активной только в том случае, если требуемое поле заполнено корректно.
. Она становится активной только в том случае, если требуемое поле заполнено корректно.
Шаги по созданию потока:
- Выбрать источник данных.
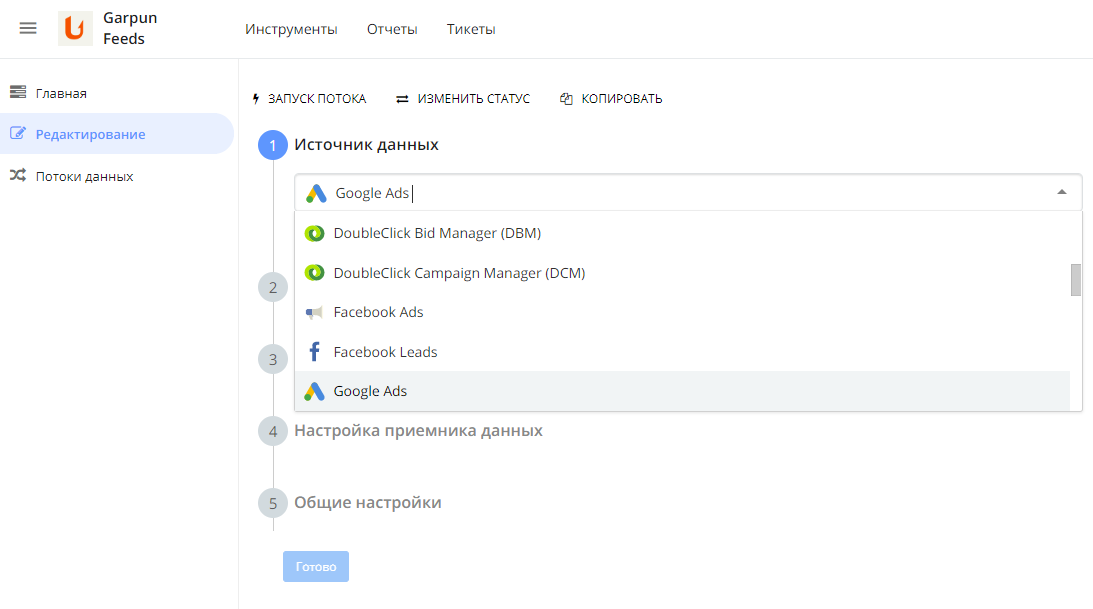
- Настройка источника данных . На этом этапе происходит выбор набора данных , выбор аккаунта или добавление нового аккаунта, и выбор customer id.
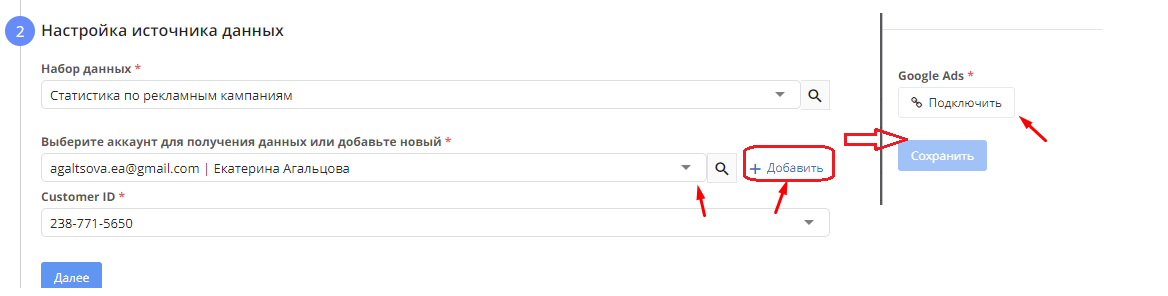
- Приемник данных. Необходимо выбрать приемник из выпадающего меню.
- Настройка приемника данных. На этом этапе нужно:
- выбрать аккаунт BQ или подключить новый.
- выбрать проект в BQ, в котором будет создана таблица с данным (Project ID)
- вписать название папки, в которую будет выгружена таблица (Dataset ID)
- вписать в поле префикс, который отобразится в имени таблицы и ее можно будет найти. Чаще всего префиксом является id аккаунта, например 1719383391484626.
 Название системы, из которой выгружаются данные, будет добавлено в название таблицы автоматически
Название системы, из которой выгружаются данные, будет добавлено в название таблицы автоматически - можно также разбить таблицу по полю, например, по полю "Date". Тогда вместо одной таблицы с данными за весь период, за каждый день будет новая таблица.
- выбрать способ записи данных в таблицу- это либо обновить данные за период либо перезаписать всю таблицу.
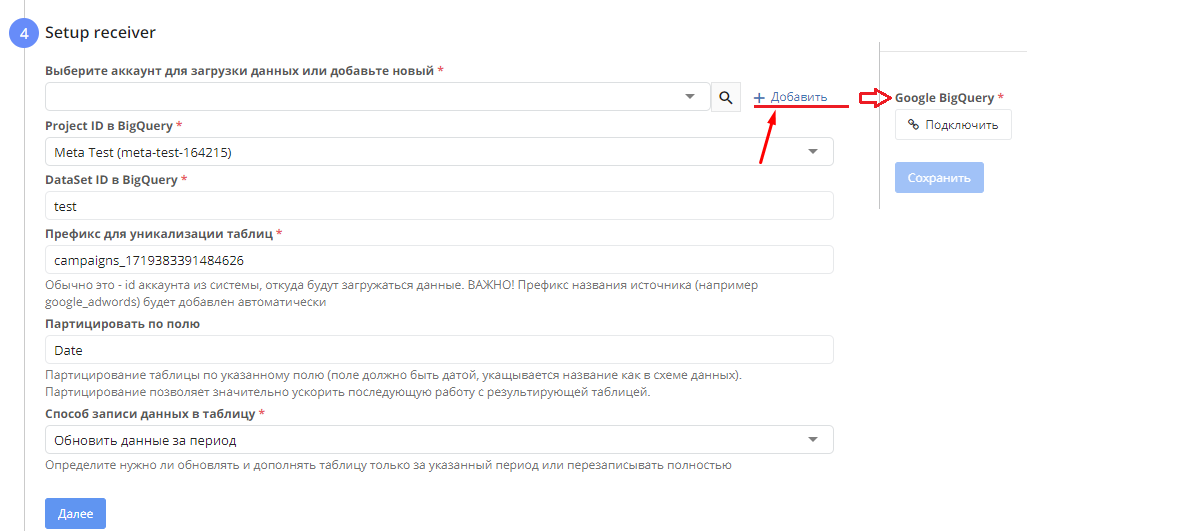
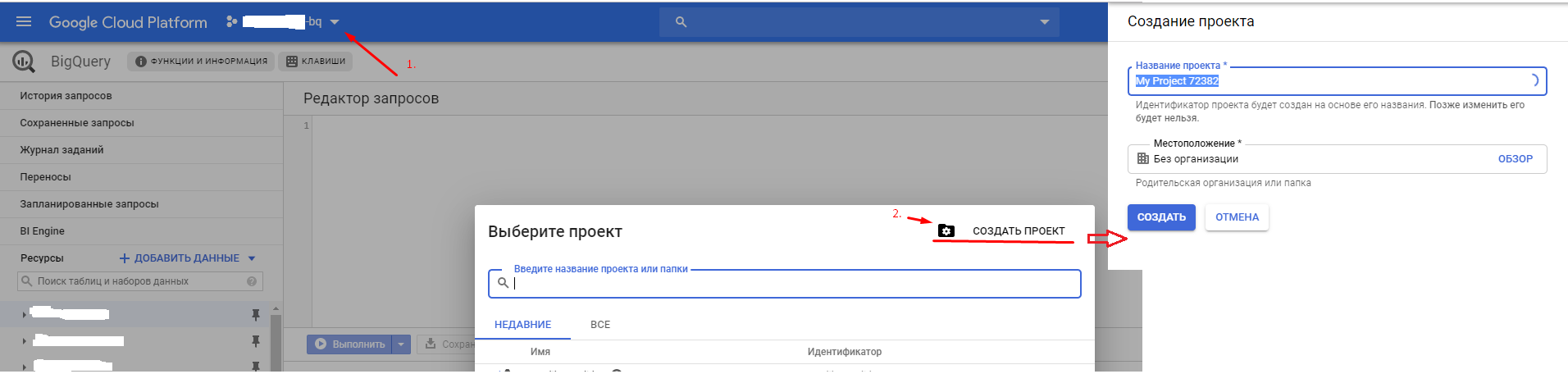
Чтобы сделать выгрузку данных в BQ нужно, чтобы в аккаунте BQ был создан проект и Dataset.
Для создания проекта вам нужно в левом верхнем меню кликнуть по кнопке для выбора проекта, в открывшемся окне нажать на кнопку .
.
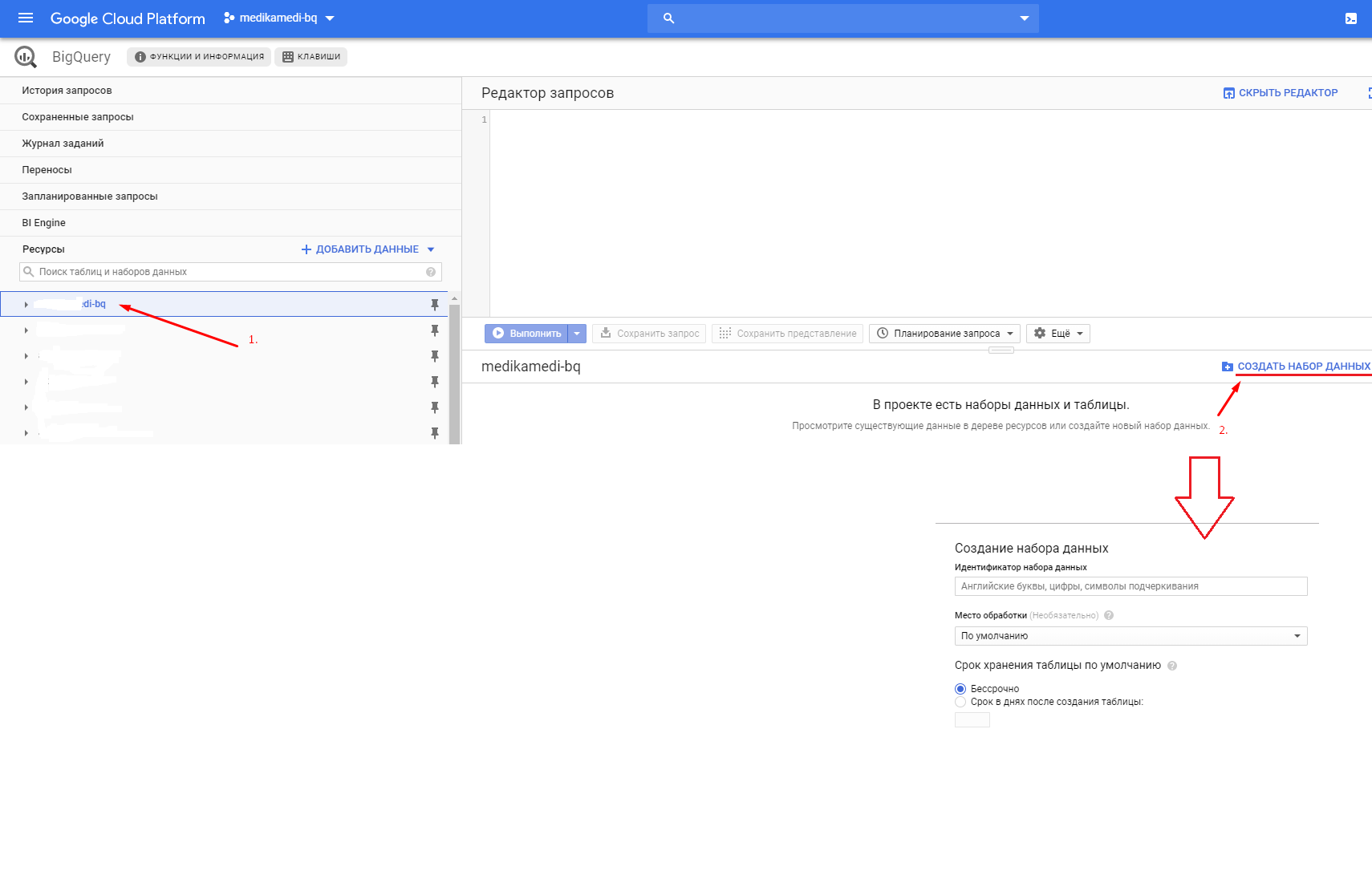
Для создания DataSet в проект нужно кликнуть по названию проекта и справа нажать на .
.
Вот, пример, как выглядит в BQ и Гарпун feeds соответствие полей: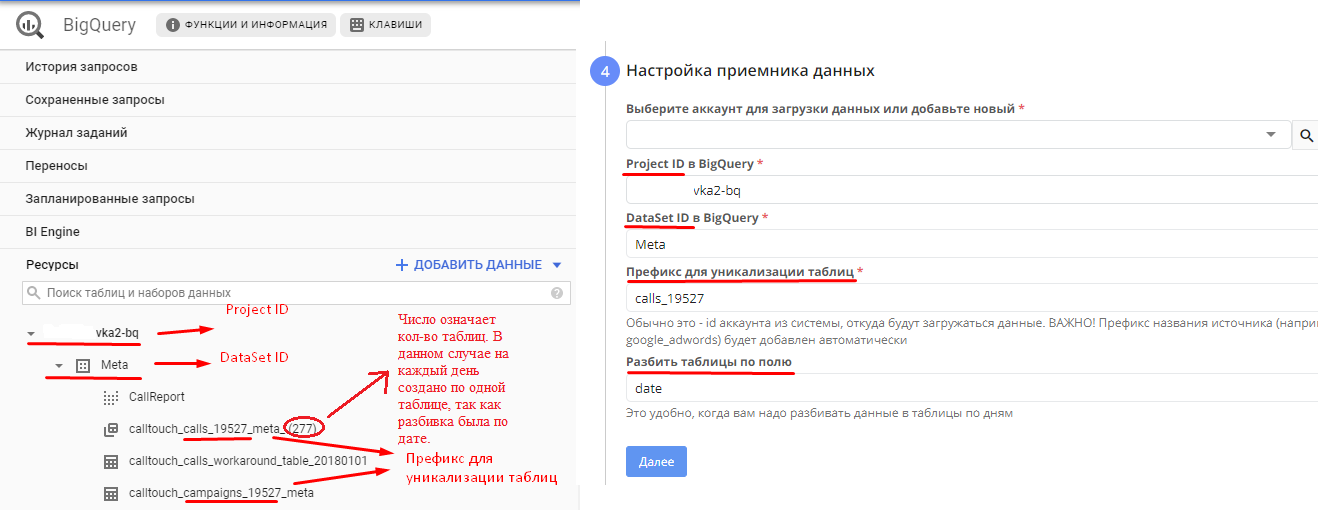
5.Общие настройки.
Здесь вам нужно задать: - Название потока , оно формируется автоматически по типу : "Yandex Direct -> Google BigQuery: Загрузка расходов (до ключей) " (то есть вы откуда происходит выгрузка/ куда/используемый набор данных). Если вас не устраивает сгенерированное автоматически название потока, то вы можете изменить его вручное, данные в поле доступны для редактирования.
- Статус. Поток может быть в статусе "Активно" или "Неактивно". Если поток будет "активным", то он будет запускаться согласно расписанию. Неактивный поток запускаться не будет.
- Клиент, которому будет выставлен счет. Если вам не нужно выставлять клиенту счет, то это поле можно оставить пустым.
- Период сбора статистики. В этом поле работает автозаполнение , автоматически выставляется вариант "на основе внутренних правил", что означает, что поток будет пересобираться за последние 30 дней. Если такой вариант вас не устраивает, вы можете выбрать другие опции: сегодня, вчера, со вчера, последние 7 дней, последние 14 дней, последние полгода, текущий год.
- Расписание. Здесь задается как часто поток будет пересобираться. Поток может пересобираться каждый час ,каждый день, каждую неделю, каждый месяц.
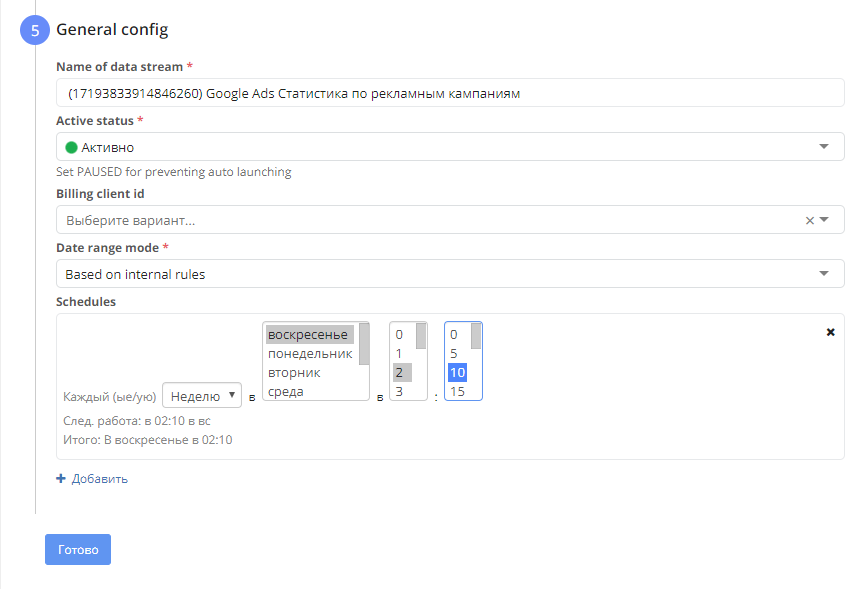
После того, как все шаги пройдены, для сохранения потока нужно нажать кнопку  .
.
Google Big Query
Чаще всего место, куда пользователи загружают данные, это Google BQ. Google BQuery - это облачное это хранилище данных, доступное через сервис Google Cloud. Оно удобно своей простотой использования. К данным можно обращаться с помощью SQL запросов.
Более подробно о сервисе BQ вы можете прочитать здесь: https://netpeak.net/ru/blog/google-bigquery-podrobnyy-obzor-funktsii/
Пример таблицы в BQ, которая была создана с помощью Garpun Feeds:
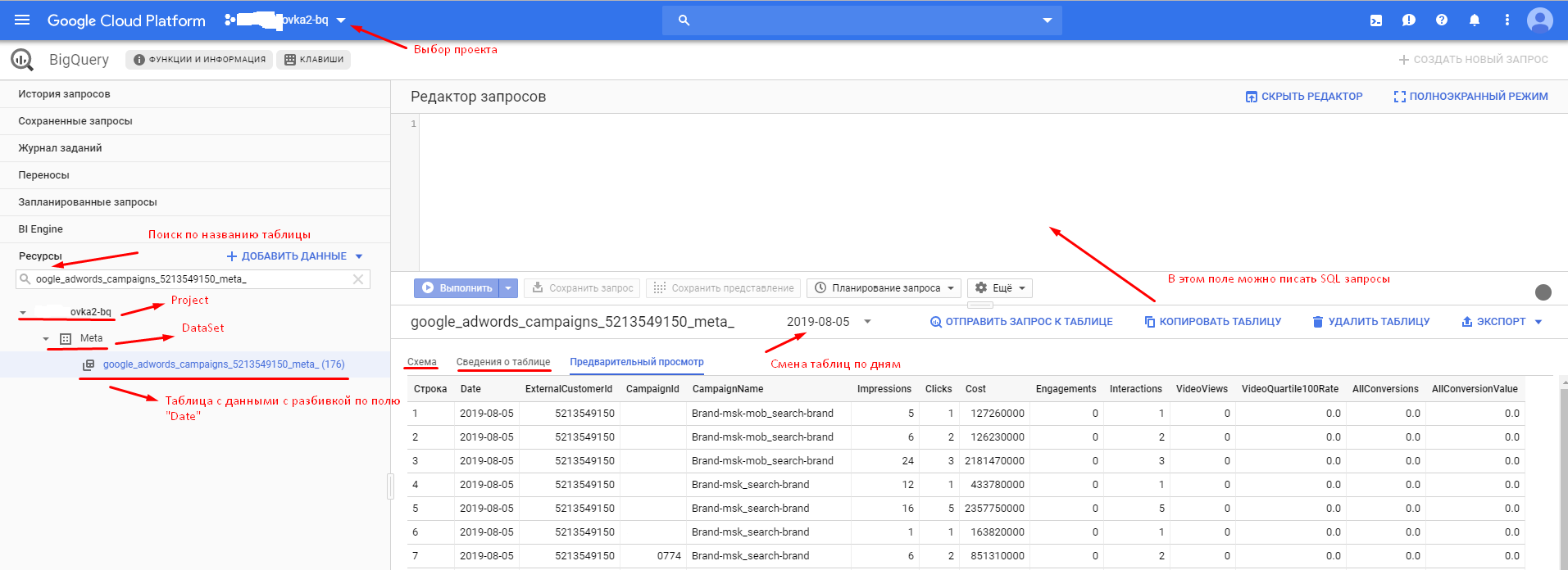
После того, как необходимые данные будут выгружены в BQ, вы можете их визуализировать в отчетах Data Studio или Power BI.
Data Studio
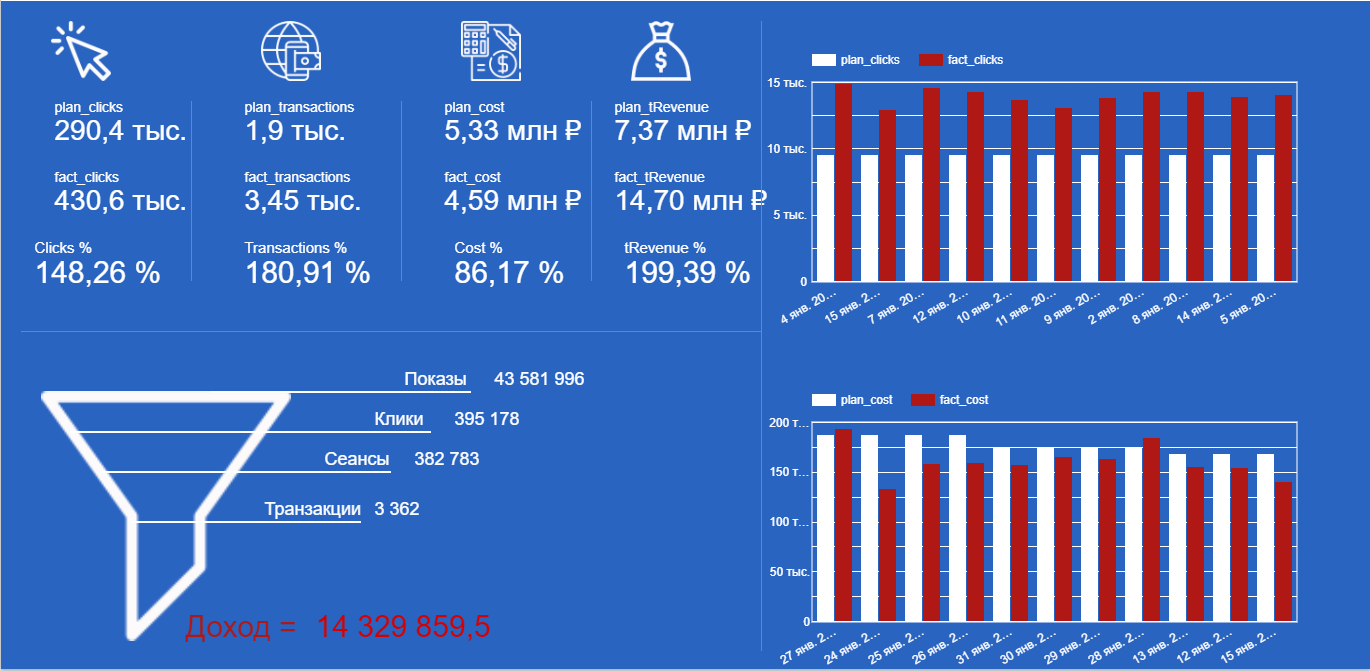
Пример отчета в DataStudio по рекламным источникам:
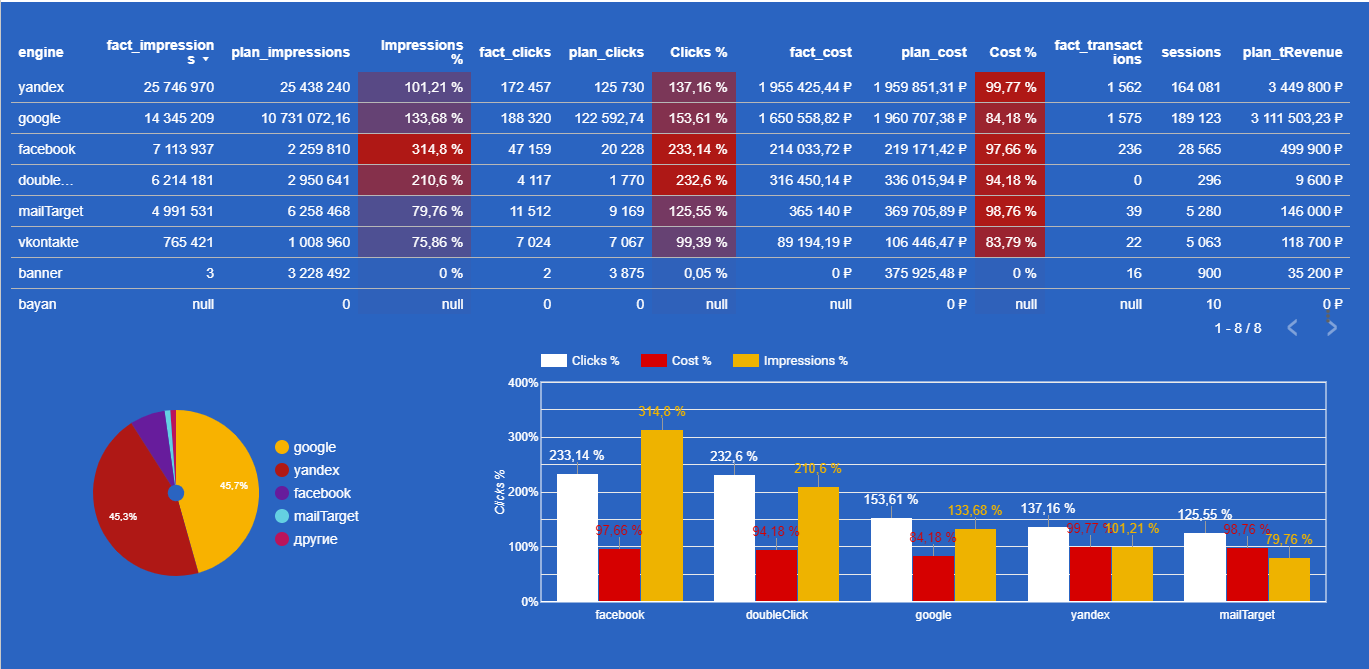
Пример отчета в DataStudio по транзакциям, кликам, расходам:
PowerBI
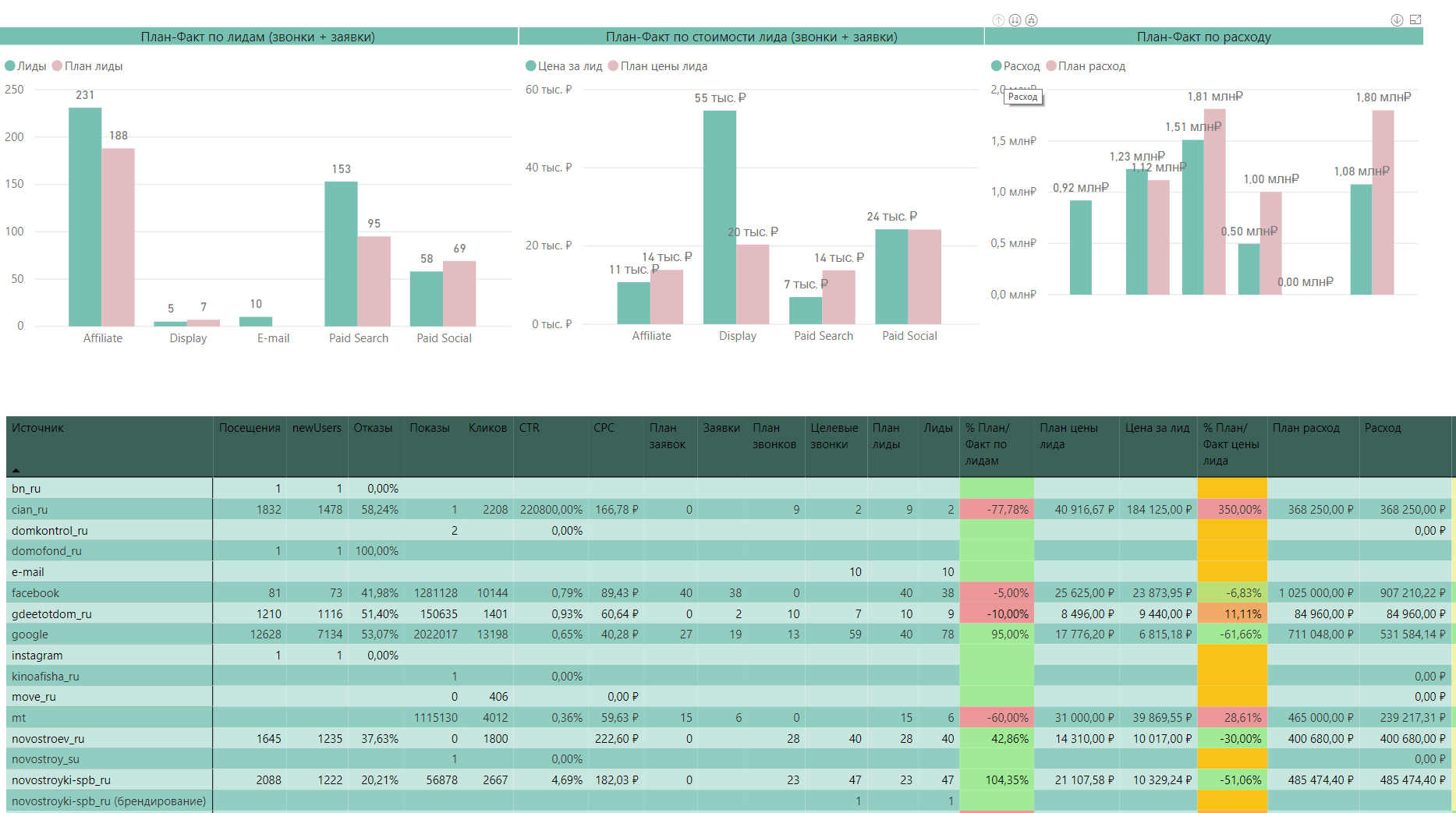
Отчеты в PowerBI формируются на основе данных из BQ c использованием скрипта на языке R или Python. Пример подобного отчета:
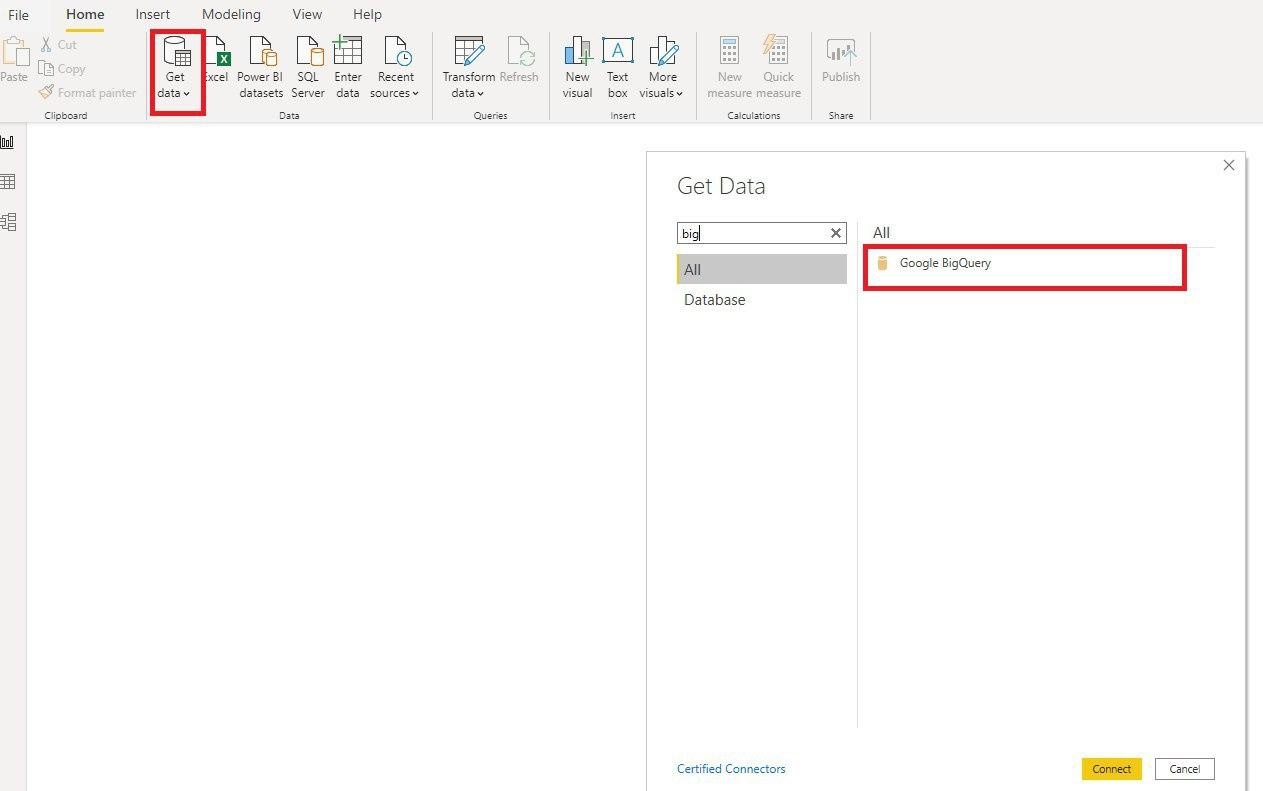
Также, в Power BI есть коннектор, который импортирует данные из GoogleBigQuery. Ниже скриншот, где его найти.
После создания ваш поток отобразится на странице Инструменты-Фиды-Потоки данных. Вы можете запускать потоки вручную. Это необходимо для того , чтобы сразу после создания запустить поток или перезапустить поток вручную при наличие ошибки и не ждать пока будет повторный автоматический запуск потока.Слева от названия потока есть значок  , нажав на которые выйдет контекстное меню.
, нажав на которые выйдет контекстное меню.
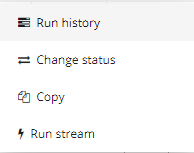
С помощью него вы можете посмотреть историю срабатываний потока, запустить поток вручную, изменить статус потока, копировать поток для создания нового.
В истории запусков можно увидеть в какое время запускался поток, за какой период пересобирались данные, статус потока, стадия потока, тип ошибки, длительность операции сбора данных, кол-во попыток, кто запускал поток. Над историей срабатываний есть кнопка  , эта кнопка запускает пересбор за тот временной промежуток, который был задан на 5-ом шаге создания потока в строке "Период сбора при автоматическом запуске".
, эта кнопка запускает пересбор за тот временной промежуток, который был задан на 5-ом шаге создания потока в строке "Период сбора при автоматическом запуске".
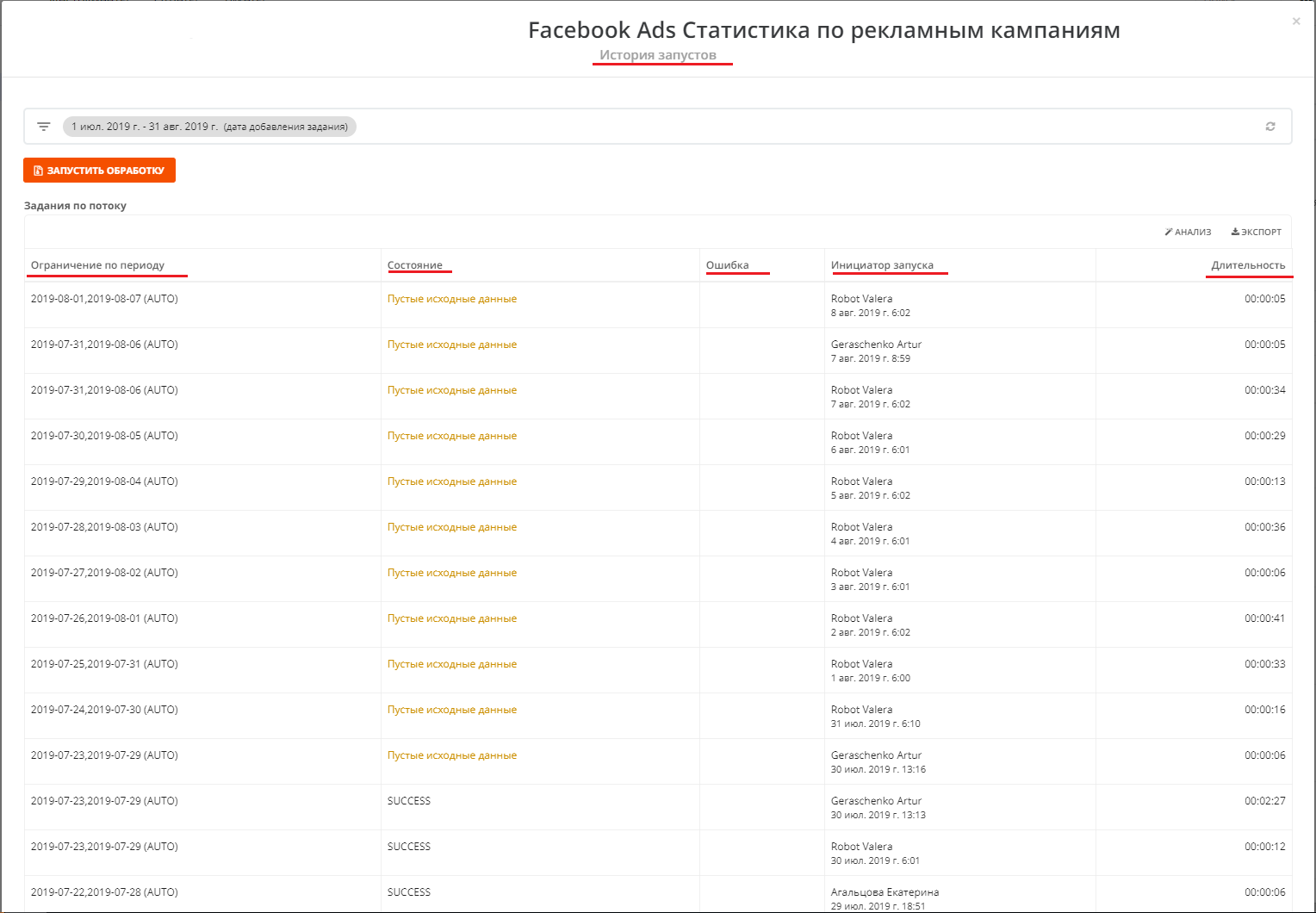
. При клике на кнопку![]() вы можете выбрать период, за который нужен пересбор и нажать "Запустить обработку".
вы можете выбрать период, за который нужен пересбор и нажать "Запустить обработку".

С помощью кнопки ![]() можно активировать или деактивировать поток. Неактивный поток не будет запускаться согласно расписанию и периоду сбора.
можно активировать или деактивировать поток. Неактивный поток не будет запускаться согласно расписанию и периоду сбора.
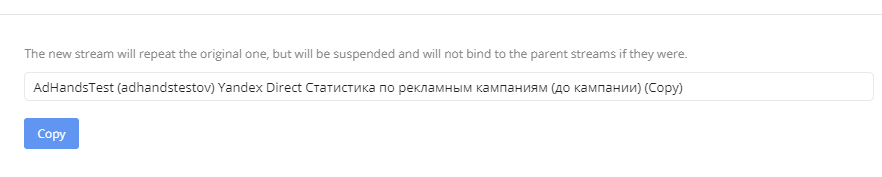
Кнопка ![]() позволяет скопировать поток. Новый поток будет повторять исходный, но будет приостановлен и не будет привязан к родительским потокам.
позволяет скопировать поток. Новый поток будет повторять исходный, но будет приостановлен и не будет привязан к родительским потокам.
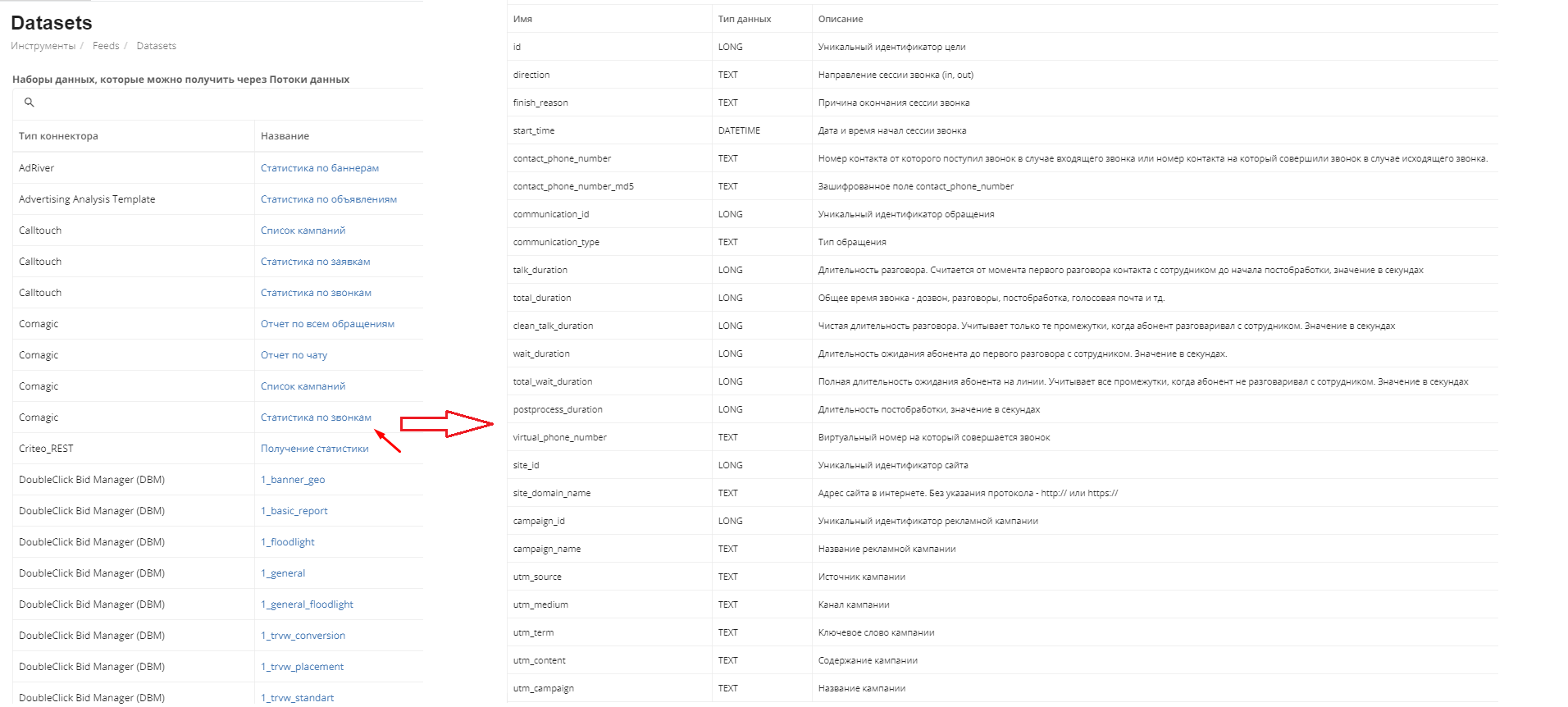
Наборы данных
Здесь находятся наборы данных, которые вы можете использовать при создании своих потоков (шаг 2 " Настройка источника данных")
Сейчас существует 74 набора данных. Тип коннектора означает из какой системы будет грузится поток с этим набором данных. Для того, чтобы посмотреть более подробно, что содержится в том или ином наборе данных, нужно кликнуть на название.
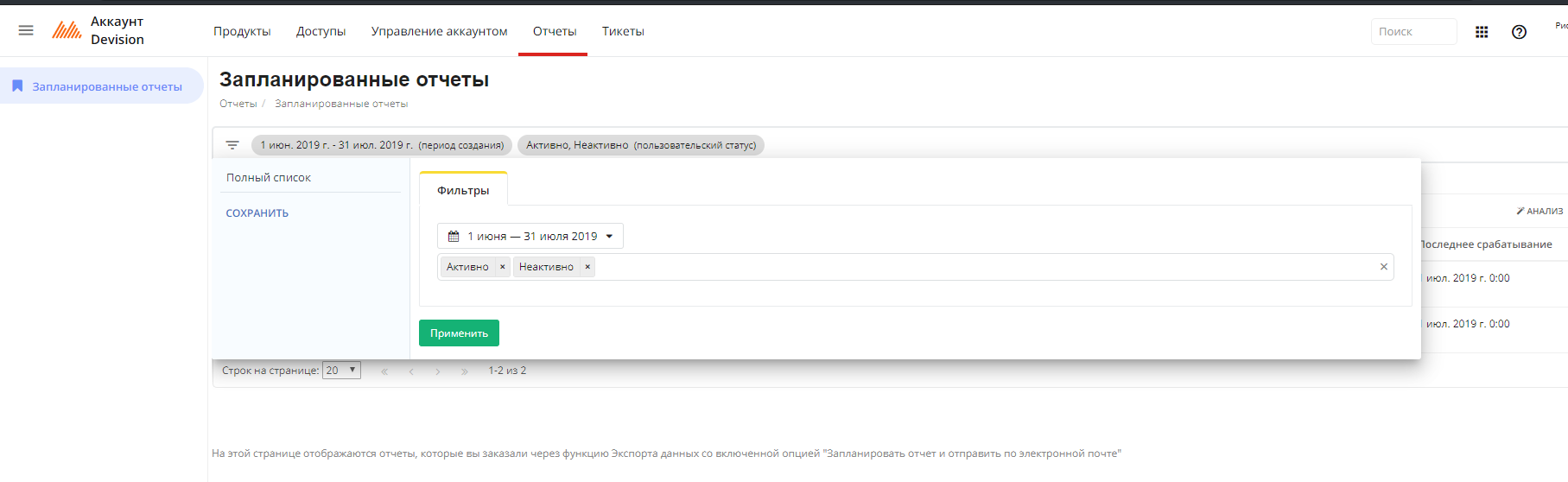
Отчеты
Отчеты можно фильтровать по дате и по статусам (Активно/Неактивно).
Тикеты
На страницы "Тикеты" реализована фильтрация тикетов (запросов) по периоду, типу периода, статусу, типу запросов, исполнителю и автору. Помимо этого есть смарт фильтры с помощью которых ,например, можно исключить или оставить определенный тип тикетов используя параметр "точно соответствует" или "содержит". По вкладкам, которые расположены ниже, можно выбирать "Открытые" или"Закрытые" тикеты.
На этой же странице можно создать новый тикет через кнопку с типами "Обращение в тех. поддержку" и "Идеи по новому функционалу".
В самом тикете внутри можно изменить статус, поменять тему и описание, прикрепить файлы, добавить комментарии к тикету.
Во вкладке "История" можно посмотреть какие действия совершались по тикету.
Помимо этого, для быстрого перехода в тикеты можно использовать значок который находится в верхнем правом углу страницы.
который находится в верхнем правом углу страницы.